想要有更强的竞争力,这部分一定是得学的,并且小公司的话,你也不太可能只仅仅开发,这些也要全要搞。多了解一些总不是坏事,想要走的更远的话。
介绍下 JDK 或者第三方的一些工具来祝你优化你的程序!
JVM参数
首先来了解下 JVM 参数的类型,一般来说,可以分为下面的三大类:
- 标准参数
在 JVM 的各个版本中基本不变,比较稳定的。
例如:-help、-server、-client、-version、-cp、-classpath - X 参数
非标准化参数,有可能会变,但是变化比较小。
例如,解释执行:-Xint、第一次使用就编译成本地代码:-Xcomp、混合模式(默认):-Xmixed - XX 参数
使用的最多的一类参数,相对不稳定,主要用于 JVM 调优和 Debug。
它还可以再分类,例如:
布尔类型:-XX:[+-]<name>表示启用或者禁用某个属性,启用 G1 垃圾收集器-XX:+UseG1GC。
非布尔类型,也就是 K-V 的形式:-XX:<name>=<val>就是用来调整属性的。
我们见的最多的应该是 -Xms 和 -Xmx 了,然而它俩其实是 XX 参数,是一种简写形式。
-Xms 等价于 -XX:InitialHeapSize ;-Xmx 等价于 -XX:MaxHeapSize ;-Xss 等价于 -XX:ThreadStackSize
查看JVM运行时参数
使用到的参数有:
- -XX:+PrintFlagsInitial
查看初始值 - -XX:+PrintFlagsFinal
查看最终值 - -XX:+UnlockExperimentalVMOptions
解锁实验参数,有些参数需要解锁后才可以设置。 - -XX:+UnlockDiagnosticVMOptions
解锁诊断参数 - -XX:+PrintCommandLineFlags
打印命令行参数
PrintFlagsFinal
打印的值有两类,= 表示默认值;:= 表示被用户或者 JVM 修改后的值。
可以在命令行中使用 java -XX:+PrintFlagsFinal -version 来体验一把。
jps
专门用来查看 Java 进程的,跟 Linux 中的 ps 指令类似,可以使用 jps -l 来查看详细信息,更多的参数介绍可以在官方的文档中找到。
jinfo
可以用来查看正在运行的 JVM 进程的参数,不过需要你知道参数的名字才行,例如:jinfo -flag MaxHeapSize [pid] 、查看垃圾回收器的:jinfo -flag [UseConcMarkSweepGC, UseG1GC] [pid]
jstat
可以查看 JVM 统计信息,例如类装载(-class)、垃圾收集(-gc)、JIT编译信息。
举个例子:jstat -class [pid] 1000 10 后面两个是可选的,意思是每隔 1000ms 输出一次,一共输出 10 次。
至于输出的是什么,文档里都有写,C 结尾表示的就是总量,U 结尾就是表示的已使用。
内存结构
简单起见可以参考这张图:
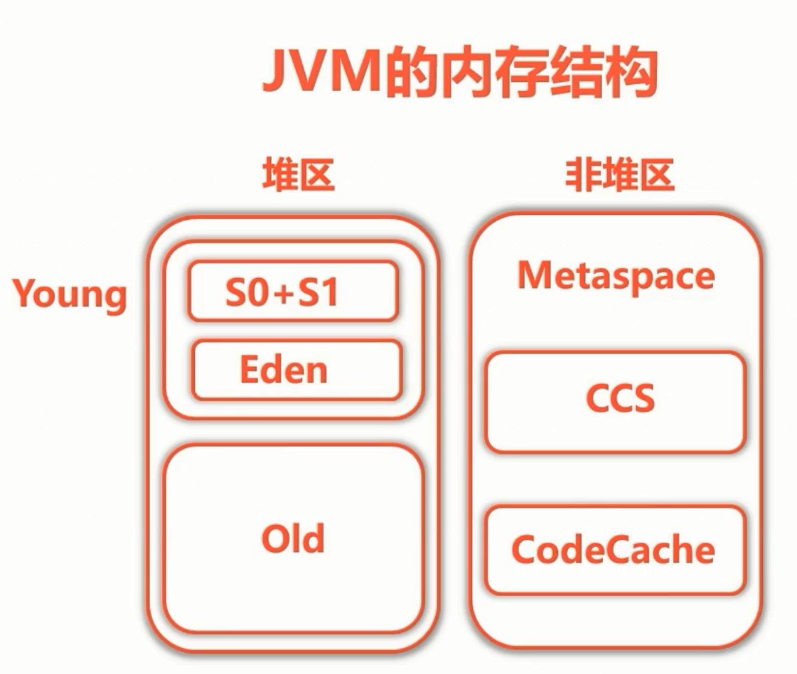
非堆区也叫 Metaspace,是 JDK8+ 才有的,它移除了永久代的概念,使用堆外直接内存;其中的 CCS 不一定存在,当启用了指针压缩(64 -> 32)才会有,CodeCache 是跟 JIT 编译相关的,还有一些其他的东西。
之前也看到过 64 位的 JVM 跟 32 位的 JVM 其实变化很大的,指针膨胀就是个大问题。
关于内存溢出
OOM 应该是常见的一种情况了,常见的分析思路就是看 Dump 文件,也就是内存镜像文件,发生 OOM 时自动导出这个文件可以这样配置:-XX:+HeapDumpOnOutOfMemoryError 、-XX:HeapDumpPath=./
除了自动导出,还可以使用 jmap 命令来手动导出。
例:jmap -dump:format=b,file=heap.hprof [pid] 、jmap -heap [pid]
使用MAT分析
这是 Eclipse 的一个工具,非常好用,官方地址:https://www.eclipse.org/mat/
载入 hprof 文件后,主页就会展示内存占用的分布情况,并且猜测那一块会有 OOM 的可能。
常用的就两个功能,查看对象的数量和查看对象占用的内存,一般来说只看强引用就行。
这个软件的详细用法 Google 一下。
死循环与死锁
这里要介绍下 jstack 这个命令,它可以看到线程信息,当发现我们的 CPU 飙高,就有可能发生了死循环或者死锁的情况。
使用 jstack 输出指定 pid 的情况,然后重定向到一个文件里,拿下来分析就好了。
PS:使用 top -p [pid] -H 命令可以查看某个进程里面的线程情况,使用 printf "%x" xxx 可以将十进制的 pid 转换为 16 进制。
jvisualvm可视化
jvisualvm 是 JDK 自带的一个工具,使用它可以可视化的监控 Java 程序的运行情况,当然,远程的也是可以进行监控的,不过需要设置了 JMX 才行。
然后,它可以安装第三方插件,推荐的两个插件是:VisualGC 和 BtraceWorkbench。
插件地址:http://visualvm.github.io/pluginscenters.html
需要先把对应版本的源添加进配置里才可以下载安装。
并且官网是有中文版的教程的,可以看一看。
Btrace调试
它的作用是在我们的应用程序不重启不修改,正在运行的情况下动态修改字节码,达到监控调试的目的。
使用步骤按照官方文档,设置个 BTRACE_HOME 的环境变量就可以了,运行方式有两种,一种直接命令行:btrace <PID> <trace_script> ,另一种可以使用 jvisualvm 插件来配合实现。
脚本代码非常简单,跟我们的 Java 代码也很类似(拦截器),所以不要怕。
至于下载地址,在 Github 上搜就可以了,项目主页:https://github.com/btraceio/btrace
脚本示例:
1 |
|
编写脚本所依赖的几个 jar 包在你下载的安装包里都有,使用也非常简单,直接跟类名就行,他没有包的概念,并且跟程序是独立的。
使用 -cp 来指定额外的 classpath 依赖第三方的类库。
拦截方法
包括构造方法也是可以的,使用的是字节码风格 <init>。
默认是在入口的时候进行拦截,其他的拦截时机:
- ENTRY:入口(默认)
- RETURN:返回
- THROW:异常
- Line:行
如果你的代码有异常,但是被 try 给吃掉了,那么如何确定代码是否抛异常了呢,可以使用官方提供的一个代码示例:
1 |
|
同样,你可以判断方法的某行代码是否执行:
1 |
|
在处理方法参数类型的时候,你可以使用 AnyType 来接收,也可以使用确定的类型。
生产环境下可以使用,但是要注意,被修改的字节码是不会被还原的,除非重启 JVM。
tomcat调试
使用 jpda 可以进行远程调试,相关的开启方法自行 Google,在配置文件中设置好端口后,在本地的 IDE 里直接填上就可以了。
tomcat 自带的管理界面比较简陋,更好的方案是使用 psi-probe 来监控,可以在 Github 上找到。
优化方面,主要着重的配置是:
- maxConnections
猫能够接受和处理的最大连接数,在 8+ 版本,使用了 NIO 技术,多路复用提高了性能。
使用 NIO 的情况下,默认是 10000 - acceptCount
当连接数超出了最大值,进入一个等待队列,这个属性控制队列的大小,默认 100 - maxThreads
配置工作线程的个数,默认是 200,同时并发处理的个数。 - minSpareThreads
最小空闲的工作线程数,不要太小。 - enableLookups
使用request.getRemoteHost()时进行 DNS 查询,建议禁用,8.5 默认禁用。 - autoDeploy
猫运行时,要不要周期性的检查是不是有新应用需要部署,需要开一个线程来周期性检测,生产环境要关闭,默认开启。 - reloadable
来监控/WEB-INF/classes/和/WEB-INF/lib的变化,同理建议禁用,8.5 默认禁用。
开发环境,用来支持热加载还是不错的。 - protocol
在 server.xml 文件中配置,8+ 版本默认的使用 NIO,如果是高并发可以尝试使用 APR ,它使用的是 native 方法,性能会有一定提升。 - 分布式情况下,如果使用了 SpringSession 类似的解决方案,建议禁用猫的 session,尤其是使用 JSP 的时候。
参考文档:docs/config/http.html、docs/config/host.html、docs/config/context.html
nginx优化
配置文件的解读就不说了,Google 很多,要注意的是,配置反向代理要关闭 selinux,setenforce 0。
使用 nginx -V 可以查看编译参数。
使用 nginx 提供的 ngx_http_stub_status 配置来监控连接信息,要使用它需要将这个模块加入编译参数才行。
1 | location = /nginx_status { |
还有一个好用的工具 ngxtop,使用 python 的 pip 包管理直接 install 就好。
在 Github 上可以找到它的官方文档(不过这个项目已经不活跃了)。
1 | 基本使用 |
再来介绍另一款图形化的监控工具:Nginx-rrd,这个是基于 PHP 来做的,所以需要 PHP 的相关依赖,然后需要在 php-fpm 中跟 nginx 统一用户,具体的配置还蛮多的,可以去 Google 一下。
它的原理是使用定时任务来扫描,每次都会存储成一张张的图片,最后使用 web 端来进行展示。
PS:这些监控工具都是基于 ngx_http_stub_status 来做的,所以上面那个 location 配置不能少。
一些常见的基本的 Nginx 优化:
- 增加工作线程数和并发连接数
默认情况下,Nginx 只有一个工作线程,并发数为 1024。 - 启用长连接
默认对客户端使用的是长连接,也可以对反向代理的后端使用长连接。 - 启用缓存、压缩
- 操作系统参数优化
下面见一个示例的配置文件:
1 | # 配置工作线程,受限于 CPU 的数量,一般配置与 CPU 的数量相等。 |
然后可以使用 nginx -t 来测试下配置文件是否正确。
开启缓存和压缩:
1 | # 开启gzip |
操作系统参数优化:
1 | /etc/sysctl.conf |
更多详细配置参考:
https://wsgzao.github.io/post/sysctl/
https://imququ.com/post/my-nginx-conf-for-wpo.html
http://sfau.lt/b5DA5u
垃圾回收
如何选择垃圾收集器呢?
- 优先调整堆大小,让服务器自己来选择
- 如果内存小于 100M,使用串行收集器
- 如果是单核,并且没有停顿时间的要求,串行或者 JVM 自己选
- 如果允许停顿时间超过 1 秒,选择并行或者 JVM 自己选
- 如果响应时间很重要,并且不能超过 1 秒,使用并发收集器
几种垃圾收集器在之前的笔记里都有介绍,这里只作补充。
对于并行的 GC,是有自适应的特性的,就是说你给定几个指标(吞吐量、停顿时间等)它会自动调整堆大小,但这不是最优的方案,因为动态调整也是消耗性能的。
对应 Web 应用,我们还是比较关注停顿时间的,所以一般都是用并发的 GC,例如 CMS,这类收集器是对 CPU 敏感的,虽然跟用户线程并发执行,但是用户线程的 cpu 资源就少了,并且会产生浮动垃圾和空间碎片,在 G1 出现之前使用还是非常广泛的,在 J8 中官方推荐使用 G1。
G1 在 JDK7 开始提供,到 J8 已经比较成熟了,适用于大内存、低停顿的场景,在 J9 里 G1 已经成为默认的收集器,并且将 CMS 设置为废弃。
在 G1 中,老年代新生代是逻辑上的称呼了,它将堆分为一个个的 Region,还有一些成为 H 区用来存放大对象(超过了 Region 的一半)。
G1 中的 YoungGC 和传统的并没有什么区别,但是它没有了 FullGC,多了个 MixedGC,它回收所有 Young 和部分 Old,它也有并发标记的过程,默认堆的占有率达到 45% 就会触发。在每次 YGC 之后和 MGC 之前,会检查垃圾占比是否达到了某一个阀值,只有达到了才会发生 MGC。
G1 的相关概念和参数还多得多,这里不再一一举例。
G1 最佳实践:
- 年轻代大小避免使用 -Xmn、 -XX:NewRatio 等显式设置,会覆盖暂停时间目标值
- 暂停时间目标时间不要太严苛,其吞吐量目标是 90% 的应用程序时间和 10% 的垃圾回收时间,太严苛会直接影响吞吐量。
当发生了下面的几种情况,可以考虑切换到 G1 了:
- 50% 以上的堆被存活对象占用
- 对象分配和晋升的速度变化非常大
- 垃圾回收时间特别长,超过了 1 秒
调优的过程就是在吞吐量和响应时间之间找平衡的过程,并且……在 J12 又带来了新的收集器 ZGC….。
日志分析
既然是分析日志,那么首先得拿到日志,使用这些参数来开启,然后就有日志文件了,直接读也是可以的,不过可视化更方便,可以使用这个在线分析,或者使用 GCViewer(在 Github)
1 | -XX:+PrintGCDetails |
GC调优
先来看并行的 ParallelGC,指导原则:
- 除非确定,否则不要设置最大堆内存
- 优先设置吞吐量目标
- 如果吞吐量目标达不到,调大最大内存,不能让 OS 使用 Swap,如果仍然达不到,降低目标
- 吞吐量能达到,GC 时间太长,设置停顿时间的目标
这些在 Oracle 官方文档里都有写的。
关于 G1 的调优,参考上面的 G1 最佳实践规则就可以了。
调优过程要一个参数一个参数的设置,避免不知道是改的那个参数起的作用,然后这是个循序渐进的过程,不太可能一步到位的。
这一块的内容,还是去慕课网看视频比较好,文字不太好描述。
其他
JVM 是基于栈的架构,相比经典的基于寄存器的架构来说,它的指令更短,但是指令数量会更多。
例如一个经典的问题,i++ 和 ++i 那个效率高,在 fori 循环里是很常用的,可以分析字节码,会发现这两种形式翻译的字节码是一样的,所以他们的效率其实是一样的。
然后再看下面的一段代码:
1 | public String test(){ |
那么到底返回的是那个呢,答案是 hello,通过字节码可以看出,因为字符串是不可变对象,会将 hello 和 ll 同时压入两个本地变量,在走到 return 的时候把第一个也就是 hello 返回,然后又将第二个 ll 赋值给了第一个本地变量。
我们知道在使用 + 进行字符串拼接时,默认会转换为 StringBuilder,那么这是绝对的么?
1 | public static void f1(){ |
可以去分析字节码,这里就直接说结论,当 String 类型为 final 时,是在编译阶段就直接确定了,不会再进行拼接。
关于 String,还有一个很有趣的地方:
1 | public static void main(String[] args){ |
在 JDK7- 和 JDK7+ 结果是不一样的,之前是两个 false,之后变成了 false 、 true,原因就是在 J7 之后字符串常量池移到了堆中,当使用 intern 方法并且常量池没有,堆中有的情况下,会将堆中的这个引用放到常量池中(常量池已经在堆中了),这样 s3 和 s4 就相等了。
G1 还有个字符串去重的功能(需要手动开启),也就是我们程序中字符串常量是占了很大比重的,而堆中和常量池中都有的话是很浪费的,当堆中字符串生命周期很长(有个阀值)就会触发去重操作。
常见的代码优化:
- 尽量重用对象,不要循环创建对象,比如:for 循环字符串拼接
- 容器类初始化的时候指定长度(List、Map)
- 集合遍历尽量减少重复计算(例如条件是不确定的 size)
- 尽量使用 Entry 来遍历 Map
- 尽量使用基本类型而不是包装类型
- 及时消除过期对象的引用,防止内存泄露
- 尽量使用局部变量,减小变量的作用域
- ThreadLocal 缓存线程不安全的对象 SimpleDateFormat(J8 可以直接用新的 API DateTimeFormat 它是线程安全的)
- 尽量使用延时加载,例如单例模式(内部静态类)
- 尽量减少使用反射,用的话也尽量加缓存
- 慎用异常,不要用抛异常来表示正常业务逻辑,因为抛异常是比较重的操作,但是也别为了这个而不用,有些地方该用就得用。
- String 操作尽量少用正则
又一个有趣的例子:
1 | public void test(){ |
这是因为 Integer 会自动缓存一个字节的数字,如果在缓存中直接返回,如果不在才 new,其他有的包装类型也有部分有缓存,比如 Long,不过 Double 这种肯定是没有的啦。


评论框加载失败,无法访问 Disqus
你可能需要魔法上网~~