MyBatis 是一个 Java 持久化框架,它通过 XML 描述符或注解把对象与存储过程或 SQL 语句关联起来。
MyBatis 是在 Apache 许可证 2.0 下分发的自由软件;MyBatis 的前身是 iBatis ,是 Apache 的一个开源项目
由于 MyBatis 是直接基于 JDBC 做了简单的映射包装,所以从性能的角度来看:
JDBC > MyBatis > hibernate
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
整体架构
首先来看下 MyBatis 的整体架构,有一个大体的了解,相比 Hibernate 真是简单多了:
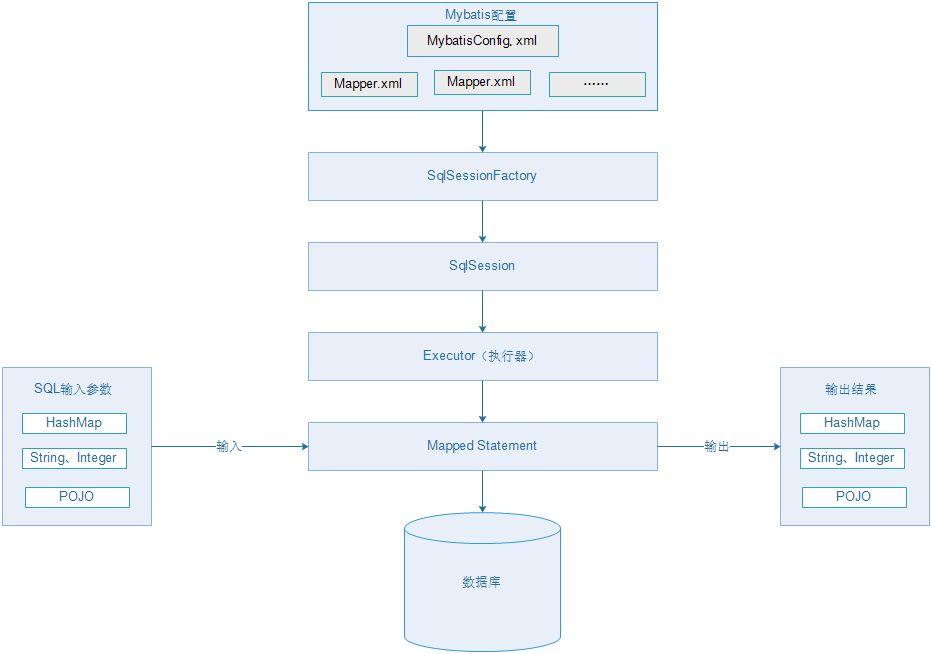
可以看出,MyBatis 也是依赖于两类配置文件,一类是主配置文件(只有一个),一般约定命名为 mybatis-config.xml ,配置了运行参数、插件、连接池等信息。
还有就是 Mapper.xml 映射文件,可以有多个,里面配置的是 Statement (简单说是 SQL 也行)
执行的时候会通过主配置文件构建出 SqlSessionFactory ,然后获得 SqlSession 对象,利用 SqlSession 就可以操作数据库了
SqlSession 的底层会通过一个执行器来执行 Statement(SQL),执行器一般有两种实现,一种是基本的,一种是带有缓存功能的
前面说过 Statement 可以简单理解为 SQL 语句,一般我们写 SQL 语句都是用 ?占位符,所以需要输入参数,然后执行,返回执行结果,至于输入输出的类型,图上已经说的很清楚了
一个入门栗子
了解其的最好方法就是看文档,官方有中文文档哦,首先我们需要配置基本的配置文件:
1 | xml version="1.0" encoding="UTF-8" |
上面就是主配置文件,如果是 Maven 工程,默认是在工程的 resurces 中查找映射文件,所以可以直接写文件名;
然后来看看映射文件应该怎么写,这个映射和 Hibernate 的可不一样,简单的多,其实就是写 SQL 语句:
1 | xml version="1.0" encoding="UTF-8" |
resultType 指定的就是结果集映射到的相应的实体类,其他的先不说,看完下面的 Java 代码更好理解,下面是一段基本的 MyBatis 使用:
1 | String resource = "org/mybatis/example/mybatis-config.xml"; |
然后就可以看出,通过 session 的 selectOne 方法进行查询的时候是用 namespace.id 来定位 Statement 的
添加日志支持
按照上面的方法确实是可以执行,但是控制台没任何日志输出,也看不到执行的 SQL,如果想了解就需要添加日志支持,既然是日志,那就用大名鼎鼎的 log4j 了,MyBatis 是支持的,会自动检测,如果发现有 slf 就会加载的~所以只需要写个配置文件了。
导入依赖这个就不用说了,只要在 log4j 的配置文件中写入下面的代码即可看到效果:
1 | log4j.rootLogger=DEBUG,A1 |
简单说下意思:第一行是设置日志的等级和位置(可以随便起个名字,比如 A1),MyBatis 的许多信息都是用的 Debug 级别,可以去源码看看;
第二行是单独指定 MyBatis 的级别,第一行是全局的,相当于个性化设置;
第三行就是指定位置(A1)具体是什么,这里是控制台;
下面是布局和格式,d-时间;t-线程名;p-显示级别名;n-换行;
关于 log4j 的使用,待补充…
进行CRUD操作
下面就再深入一点,看下 MyBatis 是如何进行 CRUD 操作的:
首先来定义映射文件 UserMapper (习惯上,命名为 xxxMapper):
1 | xml version="1.0" encoding="UTF-8" |
一般一个 mapper 文件对应一个 Dao 层中的一些方法,一般来说方法名就是其 id,毕竟方法的执行需要 SQL 语句;注意下它们的标签就行了,下面 dao 层的具体实现也是都差不多,就是方法名和 SQL 语句的区别:
1 | public User queryUserById(Long id) { |
于是就会想,能不能不写这个 dao 的实现,因为感觉都是重复代码啊….最好是连映射文件也不用写…..
这是可能的,后面再说(如果连接口都不用写那就更爽了)
解决字段名于属性名不一致的问题:
最容易想的是用别名的方式,在 SQL 语句中将字段名起一个和属性名相同的别名就可以了,例如:select *,user_name userName from users 就能正确映射了
或者直接用 MyBatis 提供的功能,在主配置文件中加入:
1 | <settings> |
这样貌似更简单是吧…..但是只限于驼峰命名规则,也就是:A_COLUMN ===> aColumn
动态代理实现DAO
MyBatis 提供了使用动态代理的方式来实现 DAO,也就是说只需要写个 dao 的接口就行了,而不需要写具体的实现类;
然后先来介绍映射文件 XML 法,让我们只要配置好映射文件就不需要再写实现类:
- Mapper 中的 namespace 指定为接口
- id 对应接口中的方法名
- 接口方法中的参数必须和 Mapper 中 parameterType 配置的一致(可以省略,会根据传入值进行判断)
- 接口方法的返回值必须和 Mapper 中 resultType 配置的一致(不可省略)
满足上面四个条件应该就可以使用了,所以 dao 层接口又称为是 mapper 接口,使用的时候直接通过下面一行代码获取代理对象:
1 | // 设置事务自动提交 |
这样就省去了写 dao 实现类的时间,如果还想省去 XML 文件那么就需要使用注解了,它就是专门做这个的,关于注解等会再说
那么为什么不需要具体的实现类呢,很显然使用的是动态代理技术;源码中有个 MapperProxy 类来做这件事,它实现了 InvocationHandler 接口,当我们调用 getMapper 方法时,就会创建出相应的一个代理对象,当我们执行这个接口的方法时就会调用 MapperProxy 中的 invoke 方法,从而不需要具体的实现类了。
那么它如何找到相关的 SQL 语句呢,在 MyBatis 加载主配置文件的同时,映射文件也一同加载了,如果接口和配置文件是对应的,那么就可以利用动态代理以及反射拿到接口名、方法名等数据通过方法名等找到对应的映射配置文件,也就知道对应的 SQL 语句了。
我们使用 getMapper 方法的时候还传入了一个类,内部通过使用泛型做了强转,所以即使是返回的代理对象我们可以直接用 UserDAO 去接收。
这里的 getMapper 方法的实现应该是:
1 |
|
它是在 DefaultSqlSession 中被定义的,可以看出深层次的调用中还传入了 this (DefaultSqlSession),这是为后面调用 selectOne、selectList 等方法做准备。
在 MyBatis 加载配置文件的时候(准确说是 build 的时候),就会判断映射文件配置的 namespace 是不是个接口,如果是就做为 key (class 对象),并且根据这个接口创建一个 MapperProxyFactory 对象作为值,put 进一个叫 knownMappers 的 Map 对象中去。
在调用 getMapper 的时候,其实就是在从这个 Map 中获取相应的代理工厂,最终通过 MapperProxyFactory 的 newInstance 方法生产出一个具体的代理对象( MapperProxy ),其中会根据返回值而调用不同的 SQL 查询方法,调用会触发其 invoke 方法
configuration常用配置
因为官方有中文文档,所以可以直接去看官方的详细解释,这里写几个比较常用的以便查询
下面的配置都是写在主配置文件里的!!
属性(properties)
常用它来读取外部的配置文件(properties 文件),然后用 ${name} 来引用,让配置更加的灵活,例如可以这样定义:
1 | <properties resource="org/mybatis/example/config.properties"> |
这样是不是感觉更灵活了,读取顺序是先读取 properties 中定义的,再读取指定的文件,出现重名的情况时,文件中定义的会覆盖 xml 定义的;
从 MyBatis 3.4.2 开始,你可以为占位符指定一个默认值,但需要先开启这个功能,详情可看官方,因为感觉用的不多就不贴了
设置(settings)
第一个其实已经说过了,就是解决属性名和字段名不同的问题,会自动转换的那个(mapUnderscoreToCamelCase);
然后重点是这几个,后面会说到:
| 设置参数 | 描述 | 有效值 | 默认值 |
|---|---|---|---|
| cacheEnabled | 该配置影响的所有映射器中配置的缓存的全局开关。 | true / false | true |
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置fetchType属性来覆盖该项的开关状态。 |
true / false | false |
| aggressiveLazyLoading | 当开启时,任何方法的调用都会加载该对象的所有属性。否则,每个属性会按需加载(参考lazyLoadTriggerMethods). |
true / false | false (true in ≤3.4.1) |
| mapUnderscoreToCamelCase | 是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN 到经典 Java 属性名 aColumn 的类似映射。 | true / false | False |
类型别名(typeAliases)
简单说就是把 Java 类型取一个别名,在其他地方用的时候就不需要写一大堆的包了
1 | <typeAliases> |
别名的首字母是不区分大小写的,但是习惯是大写,毕竟是类;然后 MyBatis 定义了一些默认的别名,直接用就可以了:
| 别名 | 映射的类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
另外,当传入的是个数组的时候,根据源码的定义要类似这样的形式:parameterType="Object[]" ,解析配置文件的过程中在 TypeAliasRegistry 这个类中定义了这些别名。
环境(environments)
前面刚开始就用到了,用它来配置的数据库信息,因为一般都有有多个环境,比如开发环境、测试环境、生产环境;每个环境的数据库是不一样,这样做是为了便于分离
可以使用 new SqlSessionFactoryBuilder().build(reader, environment); 来指定加载某个环境的配置
实际上,都是用 Spring 来处理这个,所以了解就好
映射器(mappers)
这个是一个重点,mappers 可以通过四种方式引用:
1 | <!-- Using classpath relative resources --> |
第一种是比较熟的了;第二种通过绝对路径的方式基本不会用;第三种通过类引用就要必须将映射文件和接口文件放在一起,名字也要统一;第四种的包扫描方式也是如此,需要放在一起才行
这四种并没有想象中的那样优雅,但是好消息是,和 Spring 整合后就能使用更优雅的方式了,不用和类混在一起也不需要配置那么多 mapper,等下篇说吧
Mapper常用配置
这里所有的配置都是写在映射文件中的哦。
这方面官方文档中写的也是非常详细的,也是挑常用的说,SQL 映射文件有很少的几个顶级元素(按照它们应该被定义的顺序):
cache– 给定命名空间的缓存配置。cache-ref– 其他命名空间缓存配置的引用。resultMap– 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。sql– 可被其他语句引用的可重用语句块。insert– 映射插入语句update– 映射更新语句delete– 映射删除语句select– 映射查询语句
最后的四个其实已经用过了,对应 CRUD 操作,对它们还是有些补充的东西;
对于 insert/update,如果设置的是 id 自动增长,插入一条数据后是获取不到 id 的,为了让 id 回填,需要配置一些东西(下表加黑的属性):
| 属性 | 描述 |
|---|---|
| id | 命名空间中的唯一标识符,可被用来代表这条语句。 |
| parameterType | 将要传入语句的参数的完全限定类名或别名。这个属性是可选的,因为 MyBatis 可以通过 TypeHandler 推断出具体传入语句的参数,默认值为 unset。 |
| flushCache | 将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:true(对应插入、更新和删除语句)。 |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为 unset(依赖驱动)。 |
| statementType | STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
| useGeneratedKeys | (仅对 insert 和 update 有用)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系数据库管理系统的自动递增字段),默认值:false。 |
| keyProperty | (仅对 insert 和 update 有用)唯一标记一个属性,MyBatis 会通过 getGeneratedKeys 的返回值或者通过 insert 语句的 selectKey 子元素设置它的键值,默认:unset。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| keyColumn | (仅对 insert 和 update 有用)通过生成的键值设置表中的列名,这个设置仅在某些数据库(像 PostgreSQL)是必须的,当主键列不是表中的第一列的时候需要设置。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| databaseId | 如果配置了 databaseIdProvider,MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略。 |
简单来说是 useGeneratedKeys 开启回填 id;keyColumn 指定数据库中的列(如果和 keyProperty 相同可以省略不写);keyProperty 指定对象中的属性名:
1 | <insert id="insertAuthor" |
这样插入以后获取 id 就是有值的
resultMap
官方给出的介绍是:是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象;
可以看出这个标签是很重要的,同时也看出了它的作用,就是来处理字段和属性之间的映射关系的,所以它也是可以处理字段名和属性名不同的问题,例如:
1 | <!-- 定义 --> |
其中 resultMap 有一个 autoMapping 自动映射的属性,开启后如果没写的字段也会进行映射,也就是不用写全,这个默认应该是开启状态(当使用了集合等标签默认是关闭),但还是写上比较好
sql片段
sql 片段就是为了 sql 代码的复用,和 Java 代码类似,如果有很多重复的 sql 语句,可以提取出来,也便于以后的统一维护;
一般情况下,我们会把这些 sql 片段统一在一个单独的 mapper 文件中,就像 Java 中的工具类;下面就来看看 sql 片段的写法和使用:
1 | <sql id="userColumns"> ${alias}.id,${alias}.username,${alias}.password </sql> |
使用 include 标签来引用,在这其中可以使用 property 标签来指定片段中引用的值
$与#.
在 Mapper 中,参数传递有两种方式,一种是 ${} 另一种是 #{} 它们有很大的区别;
#{}是实现的 sql 语句的预处理,之后执行的 sql 中会用 ?来代替,不需要关注数据类型(自动处理),并且能防止 SQL 注入,因为本质是占位符,所以名字其实可以随便写(#{xxx}),最后都会换成 ?,前提是参数是基本数据类型;${}是 SQL 语句的直接拼接,不做数据类型转换,需要自行判断数据类型,不能防止 SQL 注入;
当我们的表名不确定时,就可以使用 $ 了,select * from ${tabName} ,表名可以通过参数传递过来,如果使用 # 那么最终的 sql 语句就会变成:select * from ? ,当然会报错;
使用 $ 时要注意的是它默认会从传入的对象中找 getter 方法获得配置的名(# 也是类似,但当传入的是基本数据类型时名称其实可以随便写),例如,你传入的是一个字符串类型的表名,但是它会调用 String.getTabName() 方法,自然会报错,所以你知道为什么前面 CRUD 的时候一条 SQL 可以使用多次 #{name} 了吧。
解决方法有两种:
- 使用
${value},这样就会获取默认传入的参数,它是 MyBatis 中提供的默认参数名 - 代码中使用注解 ( @Param )
public List<Map<String,Object>> queryByTableName(@Param("tabName") String tabName);
还记得那张架构表么,resultType 的类型是可以设置为 Map 的,不过 Map 是个接口,需要写具体类,比如 HashMap;
多个参数
当传入的是多个参数的时候,就和 #{name} 中的名字有关了,但是你直接写肯定是不行的,方法也是有两种:
- 使用
#{0}、#{param1}这样依次增加 - 代码中使用 @Param 注解,然后就可以使用
#{name}的形式了
优先选择的当然是注解了,这样看着比较舒服….
单个参数的时候 # 是与参数名无关的,最终反正会被替换成 ?
当我们传入一个对象时,可以在 SQL 中用多个
#{name}来获取对象中的属性,就像刚开始的栗子里用的一样;这种情况算是只传入了一个参数哦
使用OGNL
MyBatis 默认采用的是 OGNL 表达式,所以在这里也是可以使用的,在写 SQL 的时候写的 #{name} 中就可以使用,还可以用在一些标签里面(比如 if 里的 test 表达式)。
获取几种值的写法(对大小写敏感),例如获取基本数据类型是 #{_parameter}:
获取基本类型:_parameter
自定义类型:属性名
获取集合:数组(用 array)、List(用 list )、Map(用 _parameter );例如:对于基本数据类型的数组:array[索引]
如果是 Map 的话就是 _parameter.key ,自定义的类型(Map<string,obj>) 可以直接 key.属性名 获取
在 OGNL 中可以直接使用 Java 中的操作符(+、-、/、==、!=、||、&&),以及调用 Java 中的一些方法
因为是写在 XML 中,所以有些符号需要转义,于是 OGNL 提供了自己的操作符代替(and、or、in、not in、mod)mod 就是取余
所以,当 parameterType 的类型是字符串或者基本数据类型时(因为值是唯一的),并且只有一个的情况下,可以 #{_parameter} 也可以 #{随便写点啥} 或者还可以使用 OGNL 的方式直接写 _parameter
其他
因为 mapper 的定义可以省去写 dao 层接口实现类,所以很多情况下直接把原来的 dao 层命名为 mapper 层,原接口的命名 UserDAO 就写成了 UserMapper ,它们其实是指的一个东西,这样在使用 MyBatis 的情况下看着还是比较规范的。


评论框加载失败,无法访问 Disqus
你可能需要魔法上网~~