这次就不仅仅是复习了,大部分讲的是以前学习 JavaSE 的时候没有接触到的知识,并且很多情况下还是很有用的。
这篇主要讲解 Java 中的队列和线程池(包括支持周期任务的线程池),这也算得上是 SE 中的精华部分吧,当然还有一些对于日期的操作补充,平时用的也挺多的,算是非常简单的作为开胃菜~~
日期处理
代码中经常接触到日期的操作,我们不喜欢它默认的格式,大多数情况是需要进行格式化的,下面就说下最简单的格式化方式:
1 | SimpleDateFormat sf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); |
另外可以通过 date 对象获取到年月日等信息,但是很遗憾已经过时,所以就有了 Calendar, Calendar 对象用的也很多,可以看看 API;
那么他什么用呢?
我们现在已经能够格式化并创建一个日期对象了,但是我们如何才能设置和获取日期数据的特定部分呢,比如说小时,日,分钟? 我们又如何在日期的这些部分加上或者减去值呢? 答案是使用Calendar 类。
关于队列
很遗憾我看的视频里并没有讲这个,但是这个却非常的终于,好在现在知道了。
Java 中的队列 Queue 在 util 包下,它是个接口,它更倾向于是一种数据结构,也可以理解为集合吧,毕竟 Queue 是 Collection 的一个子接口,与 List、Set 同一级别。
首先来认识下什么是队列:
队列是计算机中的一种数据结构,保存在其中的数据具有“先进先出(FIFO,First In First Out)”的特性。
简单易懂的介绍,它本来也不是什么难题;在 Java 中,队列分为 2 种形式,一种是单队列,一种是循环队列 ,循环队列就是为了解决数组无限延伸的情况,让它们闭合起来形成一个圈,这就不会出现角标越界问题了。
通常,都是使用数组来实现队列,假定数组的长度为6,也就是队列的长度为6,如果不指定一般默认是 internet 的最大值。
因为 LinkedList 实现了 Queue 接口,所以定义一个接口 new 时可以直接使用 LinkedList ,但它不是同步的!
Java 中给了许多的队列实现,甚至有双端(读写)的、按优先级的,普通常用的就是阻塞和非阻塞的一些同步队列
关于阻塞队列
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
这样非阻塞也就明白了吧?
阻塞队列提供了四种处理方法:
| 方法\处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
BlockingQueue接口
阻塞队列,当队列为空是取数据阻塞,队列满,插入数据阻塞
线程安全的(批量操作不是) 是否是有界队列需要看具体的实现
常用的实现类有:
- ArrayBlockingQueue
规定大小的 BlockingQueue,其构造函数必须带一个 int 参数来指明其大小.
其所含的对象是以FIFO(先入先出)顺序排序的 - LinkedBlockingQueue
大小不定的 BlockingQueue,若其构造函数带一个规定大小的参数,生成的 BlockingQueue 有大小限制,若不带大小参数,所生成的 BlockingQueue 的大小由 Integer.MAX_VALUE 来决定.
其所含的对象是以 FIFO (先入先出)顺序排序的
是作为生产者消费者的首选 - SynchronousQueue
特殊的 BlockingQueue,对其的操作必须是放和取交替完成的 - PriorityBlockingQueue
类似于 LinkedBlockQueue,但其所含对象的排序不是 FIFO,而是依据对象的自然排序顺序或者是构造函数的 Comparator 决定的顺序
至于它是如何实现同步的,两个 ReentrantLock 读和写。
PriorityQueue类
不是按照先进先出的顺序,是按照优先级(Comparator 定义或者默认顺序,数字、字典顺序)
每次从队列中取出的是具有最高优先权的元素
内部通过堆排序实现 transient Object[] queue; 每次新增删除的时候,调整堆
非阻塞队列
非阻塞队列一般就直接实现自 Queue 了,特点就不说了,对比上面的阻塞队列就行了,下面说说常见的非阻塞队列:
ConcurrentLinkedQueue
虽然是非阻塞,但也是线程安全的,按照 FIFO 来进行排序,采用CAS操作,来保证元素的一致性
非阻塞算法通过使用低层次的并发原语,比如比较交换,取代了锁。原子变量类向用户提供了这些底层级原语,也能够当做“更佳的volatile变量”使用,同时提供了整数类和对象引用的原子化更新操作。
关键字:CAS
线程安全就是说多线程访问同一代码,不会产生不确定的结果
ConcurrentLinkedQueue 的 size() 是要遍历一遍集合的,所以尽量要避免用 size 而改用 isEmpty(),以免性能过慢。
队列的操作
一般情况下,操作队列不推荐使用 add 和 remove ,因为如果队列为空它就会抛异常;常使用的是 offer 和 poll 来添加和取出元素,如果此队列为空,则返回 null,如果使用 peek 取出元素则不会移除此元素,对于阻塞的队列,可以使用 put 和 take 来插入和获取。
带有 Deque 的一般是双端队列,不细说,我用的起码是非常少的
关于遍历队列如果使用 foreach 的方式相当于仅仅是 peek,也就是不会移除元素,如果需要遍历队列并且是取出,那么可以搭配 where 来使用:
1 | public void run() { |
这个过程注意 size,如果一边放一边遍历的话是没有尽头的
线程池
同样视频里是没有提到的,只是讲了多线程的一些使用和注意事项,对于线程池,提及的很少,也许是因为 JavaEE 中并不常用,都是交给 Web 应用服务器来维护。
如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间,和连接池是一个道理。
Java 中的线程池,最核心的就是 ThreadPoolExecutor 了
ThreadPoolExecutor 继承了 AbstractExecutorService 类,并提供了四个构造器,事实上,通过观察每个构造器的源码具体实现,发现前面三个构造器都是调用的第四个构造器进行的初始化工作。
下面解释下一下构造器中各个参数的含义:
- corePoolSize:核心池的大小
在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建 corePoolSize 个线程或者一个线程。
默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到 corePoolSize 后,就会把到达的任务放到缓存队列当中; - maximumPoolSize:线程池最大线程数
这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;
当核心池大小满了,等待队列也满了,就开始创建非核心线程,直到达到最大线程数。 - keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。
默认情况下,只有当线程池中的线程数大于 corePoolSize 时,keepAliveTime 才会起作用,直到线程池中的线程数不大于 corePoolSize,即当线程池中的线程数大于 corePoolSize 时,如果一个线程空闲的时间达到 keepAliveTime,则会终止,直到线程池中的线程数不超过 corePoolSize。
但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于 corePoolSize 时, keepAliveTime 参数也会起作用,直到线程池中的线程数为 0; - unit:参数 keepAliveTime 的时间单位
有7种取值,比如天、时、分、秒、毫秒等 - workQueue:一个阻塞队列,用来存储等待执行的任务
这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:ArrayBlockingQueue;
LinkedBlockingQueue;
SynchronousQueue;
ArrayBlockingQueue 和 PriorityBlockingQueue 使用较少,一般使用 LinkedBlockingQueue 和 Synchronous。
线程池的排队策略与 BlockingQueue 有关。 - threadFactory:线程工厂,主要用来创建线程;
- handler:表示当拒绝处理任务时的策略
有以下四种取值:
ThreadPoolExecutor.AbortPolicy :丢弃任务并抛出 RejectedExecutionException 异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
上面仅仅是对构造方法参数的一些介绍,相关的几个类或者接口就是 ThreadPoolExecutor、AbstractExecutorService、ExecutorService 和 Executor,名字越短越抽象,最后的 Executor 为顶级接口
定义的方法
下面来了解下关于线程池中定义的几个方法:
- execute()方法
实际上是 Executor 中声明的方法,在 ThreadPoolExecutor 进行了具体的实现,这个方法是 ThreadPoolExecutor 的核心方法,通过这个方法可以向线程池提交一个任务,交由线程池去执行。 - submit()方法
在 ExecutorService 中声明的方法,在 AbstractExecutorService 就已经有了具体的实现,在 ThreadPoolExecutor 中并没有对其进行重写,这个方法也是用来向线程池提交任务的,但是它和 execute() 方法不同,它能够返回任务执行的结果,去看 submit() 方法的实现,会发现它实际上还是调用的 execute() 方法,只不过它利用了 Future 来获取任务执行结果 - shutdown() 和 shutdownNow() 是用来关闭线程池的。
其他的方法还有 getQueue() 、getPoolSize() 、getActiveCount()、getCompletedTaskCount() 等获取与线程池相关属性的方法,详细介绍去看 API 吧
线程池的状态
当创建线程池后,初始时,线程池处于 RUNNING 状态;
如果调用了 shutdown() 方法,则线程池处于 SHUTDOWN 状态,此时线程池不能够接受新的任务,它会等待所有任务执行完毕;
如果调用了 shutdownNow() 方法,则线程池处于 STOP 状态,此时线程池不能接受新的任务,并且会去尝试终止正在执行的任务;
当线程池处于 SHUTDOWN 或 STOP 状态,并且所有工作线程已经销毁,任务缓存队列已经清空或执行结束后,线程池被设置为 TERMINATED 状态。
线程池的创建&使用
先来看一个简单使用的例子:
1 | public class Test { |
在 java doc中,并不提倡我们直接使用 ThreadPoolExecutor,而是使用 Executors 类中提供的几个静态方法来创建线程池:
- Executors.newCachedThreadPool();
创建一个缓冲池,缓冲池容量大小为 Integer.MAX_VALUE - Executors.newSingleThreadExecutor();
创建容量为 1 的缓冲池 - Executors.newFixedThreadPool(int);
创建固定容量大小的缓冲池
看一下他们三个的具体实现:
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
从它们的具体实现来看,它们实际上也是调用了 ThreadPoolExecutor,只不过参数都已配置好了。
newFixedThreadPool 创建的线程池 corePoolSize 和 maximumPoolSize 值是相等的,它使用的 LinkedBlockingQueue;newSingleThreadExecutor 将 corePoolSize 和 maximumPoolSize 都设置为 1,也使用的 LinkedBlockingQueue;newCachedThreadPool 将 corePoolSize 设置为 0,将 maximumPoolSize 设置为 Integer.MAX_VALUE,使用的 SynchronousQueue,也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程。
实际中,如果 Executors 提供的三个静态方法能满足要求,就尽量使用它提供的三个方法,因为自己去手动配置 ThreadPoolExecutor 的参数有点麻烦,要根据实际任务的类型和数量来进行配置。
另外,如果 ThreadPoolExecutor 达不到要求,可以自己继承 ThreadPoolExecutor 类进行重写。
配置线程池
一般需要根据任务的类型来配置线程池大小,当然也是仅供参考:
如果是 CPU 密集型任务,就需要尽量压榨 CPU,参考值可以设为 NCPU+1
如果是 IO 密集型任务,参考值可以设置为 2*NCPU
当然,这只是一个参考值,具体的设置还需要根据实际情况进行调整,比如可以先将线程池大小设置为参考值,再观察任务运行情况和系统负载、资源利用率来进行适当调整。
定时任务
一提到定时任务,首先想到的是使用 Timer,但是使用 Timer 执行周期性任务时,出现异常后自动退出(全部),因为它是基于单线程的。所以应该尽量使用 ScheduledExecutorService (支持周期任务的线程池)的方式来创建。
是的,这也是一个线程池,只不过它支持周期任务而已,看到这里对线程池应该也有所了解了,所以定时任务也就不难了
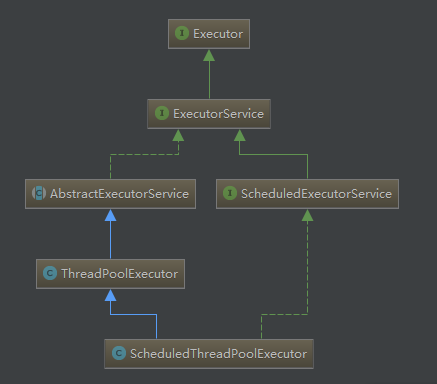
它继承的 ThreadPoolExecutor 那些就不说了,来看看它特有的几个方法:
- Schedule(Runnable command, long delay, TimeUnit unit)
elay 指定的时间后,执行指定的 Runnable 任务,可以通过返回的ScheduledFuture<?>与该任务进行交互 - schedule(Callable\
delay 指定的时间后,执行指定的Callable<V>任务,可以通过返回的ScheduledFuture<V>与该任务进行交互。 - scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit)
initialDelay 指定的时间后,开始按周期 period 执行指定的Runnable任务。
假设调用该方法后的时间点为0,那么第一次执行任务的时间点为initialDelay,第二次为initialDelay + period,第三次为initialDelay + period + period,以此类推。 - scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit)
initialDelay 指定的时间后,开始按指定的 delay 延期性的执行指定的Runnable任务。
假设调用该方法后的时间点为0,每次任务需要耗时T(i)(i 为第几次执行任务),那么第一次执行任务的时间点为initialDelay,第一次完成任务的时间点为initialDelay + T(1),则第二次执行任务的时间点为initialDelay + T(1) + delay;第二次完成任务的时间点为initialDelay + (T(1) + delay) + T(2),所以第三次执行任务的时间点为initialDelay + T(1) + delay + T(2) + delay,以此类推。
简单解释下 scheduleAtFixedRate 和 scheduleWithFixedDelay,前者会开始执行为起始点,如果任务耗时超过了间隔时间,那么在任务完成候第二次会很快(马上)执行,而后者会等待任务执行完后才开始计算周期间隔时间。
创建线程池的方式也与上面差不多,都有对应的方法:
Executors.newScheduledThreadPool(int corePoolSize)
Executors.newSingleThreadScheduledExecutor()
Apache 的 BasicThreadFactory 或许会更好….待进一步研究
补充
ScheduledFuture 接口 继承自 Future 接口,所以 ScheduledFuture 和任务的交互方式与 Future 一致。所以通过ScheduledFuture,可以 判断定时任务是否已经完成,获得定时任务的返回值,或者取消任务等
关于 Future 后面应该会再进行补充
可以先看一下:这篇文章
单例模式
这个很简单,没什么好说的,简单说就是构造函数的私有化,然后定义一个本类类型的静态变量,通过静态方法进行提供
需要注意的是,静态变量的初始化时机,比较一致的观点是:如果你确定这个类肯定要用,那么可以在定义静态变量的时候就直接进行实例化,否则可以放在静态方法中进行实例化(这样会有线程安全问题)比如:
1 | private static Singleton is = new Singleton(); |
是的,单例模式需要注意的也就是这里了:线程安全问题
如果你选择了在静态方法中进行实例化,并且使用了多线程技术,那么极有可能它并不是单例的;原因我想大概都知道,当然也有相应的解决方案,一般就从这三种中进行选择:
同步方法
这是最简单的方式,如果不考虑性能的情况下是可以使用的,使用同步就意味着可能造成执行效率下降100倍public static synchronized getInstance(){}急切实例化
这个就是上面的第一种方式,在定义的时候就直接实例化
在创建运行时负担不重的情况下可以采用双重检查加锁
在同步方法中我们发现,其实只需要第一次加锁就可以了,因为第一次创建出 is 后后面都是直接返回的
所以,可以进行下面的优化(java5+):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class Test{
private volatile static Singleton is;
private Test{}
public static Singleton getInstance(){
if(is == null){
synchronized(Test.class){
if(is == null){
is = new Singleton();
}
}
}
return is;
}
}这样可以大大减少 get 方法的时间消耗,如果确实不考虑性能,使用这个就有点大材小用了。
这个方法表面上看起来很完美,你只需要付出一次同步块的开销,但它依然有问题。
除非你声明 is 变量时使用了 volatile 关键字。没有 volatile 修饰符,可能出现 Java 中的另一个线程看到个初始化了一半的 is 的情况,但使用了 volatile 变量后,就能保证先行发生关系(happens-before relationship)
参考下面的:无序写入静态内部类
这也是一种懒汉式的实现,相比双重锁检查,更简单,更高效吧1
2
3
4
5
6
7
8
9
10
11
12public class SingletonIniti {
private SingletonIniti() {}
private static class SingletonHolder {
private static final SingletonIniti INSTANCE = newSingletonIniti();
}
public static SingletonIniti getInstance() {
return SingletonHolder.INSTANCE;
}
}加载一个类时,其内部类不会同时被加载。一个类被加载,当且仅当其某个静态成员(静态域、构造器、静态方法等)被调用时发生。
并且外部类可以访问内部类的 private 方法。
单例模式的使用情景并不是太多,并且如果程序有多个类加载器,还是会造成有多个实例的情况,所以如果用到了多个类加载器记得指定使用同一个类加载器
volatile关键字
关于这个,确实不太常见,很多人以为使用这个关键字,在进行多线程并发处理的时候就可以万事大吉。
Java 语言是支持多线程的,为了解决线程并发的问题,在语言内部引入了 同步块 和 volatile 关键字机制。
对于 synchronized 我们都知道:
通过 synchronized 关键字来实现,所有加上 synchronized 和块语句,在多线程访问的时候,同一时刻只能有一个线程能够用 synchronized 修饰的方法 或者 代码块。
用 volatile 修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最的值。volatile 很容易被误用,用来进行原子性操作。
在 java 垃圾回收整理一文中,描述了jvm运行时刻内存的分配。其中有一个内存区域是 jvm 虚拟机栈,每一个线程运行时都有一个线程栈,线程栈保存了线程运行时候变量值信息。
当线程访问某一个对象的值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存变量的具体值 load 到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。
这样在堆中的对象的值就产生变化了。原文:http://www.cnblogs.com/aigongsi/archive/2012/04/01/2429166.html
从上面的解释也可以看出 volatile 并不能保证原子性,它的作用就是在每次使用的时候获取最新的值
无序写入
双重检查锁定背后的理论是完美的。不幸地是,现实完全不同。双重检查锁定的问题是:并不能保证它会在单处理器或多处理器计算机上顺利运行。
双重检查锁定失败的问题并不归咎于 JVM 中的实现 bug,而是归咎于 Java 平台内存模型。内存模型允许所谓的“无序写入”,这也是这些习语失败的一个主要原因。
关键原因就是: instance = new Singleton(); 不是原子操作。
然后从两个方面来看原因:
- 有序性:是因为 instance = new Singleton(); 不是原子操作。编译器存在指令重排,从而存在线程1 创建实例后(初始化未完成),线程2 判断对象不为空,但实际对象扔为空,造成错误。
- 可见性:是因为线程1 创建实例后还只存在自己线程的工作内存,未更新到主存。线程 2 判断对象为空,创建实例,从而存在多实例错误。
也就是,要想保证安全,必须保证这句代码的有序性和可见性。
volatile 对 singleton 的创建过程的重要性:禁止指令重排序(有序性)。
实例化一个对象其实可以分为三个步骤:
- 分配内存空间。
- 初始化对象。
- 将内存空间的地址赋值给对应的引用。
但是由于操作系统可以对指令进行重排序,所以上面的过程也可能会变成如下过程:
- 分配内存空间。
- 将内存空间的地址赋值给对应的引用。
- 初始化对象
如果是这个流程,多线程环境下就可能将一个未初始化的对象引用暴露出来,从而导致不可预料的结果。
因此,为了防止这个过程的重排序,我们需要将变量设置为 volatile 类型的变量,volatile 的禁止重排序保证了操作的有序性。
除了这种方案,还有人提出在“构造对象”和“连接引用与实例”之间加上一道内存屏障来保证有序性:
1 | Singleton temp = new Singleton(); |
这想法确实 nice~
关于可见性,第二次非 null 判断是在加锁以后(也就是说后面的线程在获取锁以后判断 instance 是否为 null 必然是在第一个线程引用赋值完成释放锁以后),则根据这一条,另一个线程一定能看到这个引用被赋值。所以即使没有 volatile,依旧能保证可见性。
https://www.zhihu.com/question/56606703
PS:据说因为 JVM 的实现不同,volatile 未必能保证绝对的安全,在 HotSpot 应该是没问题的。
参考&拓展
http://www.infoq.com/cn/articles/java-blocking-queue
http://blog.csdn.net/xiaohulunb/article/details/38932923
https://www.cnblogs.com/dolphin0520/p/3932921.html
https://segmentfault.com/a/1190000008038848
https://blog.csdn.net/chenchaofuck1/article/details/51702129
拓展:
http://www.jianshu.com/p/925dba9f5969
深入理解Java线程池


评论框加载失败,无法访问 Disqus
你可能需要魔法上网~~