SSH 框架系列笔记,看到第二个了,Struts 原来是最简单的,后面的 Hibernate 和 Spring 都很有道道呢,尤其是 Spring ,连接了 Struts 和 Hibernate,本来是想看 Spring 的,但是发现 Hibernate 是前提,于是…..学习 Hibernate 其实就是在学习怎么配 xml 文件,因为大部分都是通过配配置文件来实现的,所以说,官方文档很重要!英语很重要! ╮(╯▽╰)╭
简介
Hibernate 是一种 Java 语言下的对象关系映射(object relation mapping)解决方案,或者说框架。它是使用 GNU 宽通用公共许可证发行的自由、开源的软件。它为面向对象的领域模型到传统的关系型数据库的映射,提供了一个使用方便的框架。
它的设计目标是将软件开发人员从大量相同的数据持久层相关编程工作中解放出来。无论是从设计草案还是从一个遗留数据库开始,开发人员都可以采用 Hibernate。
Hibernate 不仅负责从 Java 类到数据库表的映射(还包括从 Java 数据类型到 SQL 数据类型的映射),还提供了面向对象的数据查询检索机制,从而极大地缩短的手动处理 SQL 和 JDBC 上的开发时间。
数据持久化…简单说就是把数据(比如对象)保存起来,保存到文件也好数据库也好,都是持久化的体现,也许你会想到序列化,它们两个很相似,但是是两个完全不同的应用场景,持久持久,久….序列化多是为了能将对象更好的交换、传输(比如从这个线程到那个线程)
开发方式
Hibernate 一般有三种开发方式:
- 由 Domain object –> Mapping –> db ;这是官方推荐的方式
Domain 对象设计好了,Mapping 配置好了可以直接自动生成数据表 - 由 DB 开始,然后用工具生成 Domain object 和 Mapping,这种方式用的比较多
同样,数据库设计好了,也有相关的工具可以自动生成 Domain 对象和映射文件 - 由映射文件开始
然后具体解释下,Domain object 其实指的就是 javabean,也叫做 Domain 对象;Mapping 是映射文件;db 就是数据库了
它们的关系是:每一个 Domain 对象对应数据库中的一张表,每一个实例化的 Domain 对象就是数据库中对应表中的一条数据,将 Domain 对象和数据库联系起来的是数据持久层,它依赖于ORM-对象关系映射文件(Mapping);该文件会说明表和对象的关系,以及对象的属性和表字段的对应关系
对象关系映射嘛,使用了 Hibernate 基本都是操作对象了…..
Mapping 映射文件在命名上有一定规范:对象名.hbm.xml 一般放在 Javabean/Domain 对象目录(包)下,原理也都知道,就是反射,反射必须依赖于这个配置文件
简单使用
Javabean 对象和数据库就跳过了,这个很简单没啥可说的,导入相关 jar 包也不说了,关键就剩下那个 Mapping 映射文件了,当然这个完全可以自动生成,实际开发没必要手写,我第一次就手写吧
1 | xml version='1.0' encoding='utf-8' |
关于主键的策略,想深入的可移步:http://www.cnblogs.com/kakafra/archive/2012/09/16/2687569.html
上面设置的 type 除了设置 Java 类型,还可以设置 Hibernate 类型,不过一般习惯于 Java 类型
除了配置映射文件,还有一个重要的配置文件 hinernate.cfg.xml ,它用来配置数据库的类型、驱动、用户名、密码、URL 、连接池等信息;放在工程目录的根目录下,就是 Src 下,前面说的 Struts 也是
hinernate.cfg.xml 它同时还负责管理 Mapping 映射文件
1 | xml version="1.0" encoding="utf-8" |
这样操作数据库就不需要再使用 JDBC 相关的对象了,都已经被封装了;现在我们操作数据库使用的是 Hibernate 给提供的一些类和接口,最常用的有 Configuration、SessionFactory、Session、Transaction;除了第一个是类其他全是接口
使用的时候注意别导错包了,是 org.hibernate 下的包!!!
下面举个简单的栗子,使用步骤就那么几步
1 | public static void main(String[] args) { |
就是这四步走,要注意的就是进行增删改一定记得使用事务,否则不会生效,最后操作完了记得关闭连接(session)
如果不想用一个单独的变量来保存事务可以直接从 session 中获得,因为它们是绑定在一起的:session.getTransaction().commit();
按照规范,所定义的 Javabean 需要进行序列化以便可以唯一的标识该对象,并且可以进行传输
核心类和接口
上面提到过的,一个类和三个接口,此外还有一个非常重要的接口 Query ,非常强大
Configuration类
这是唯一的一个类了,它的作用就是读取(加载)配置文件的,当然也包括映射文件,加载一些驱动啥的
这个类还是很简单的,就不多说了
SessionFactory接口
它的一些特点:
- 缓存 SQL 语句和某些数据(一级缓存,又叫 Session 缓存)
- 在程序初始化的时候创建,因为特别吃资源,一般采用单例模式保证一个应用中只有一个
- 如果一个应用要使用多个数据库,那么可以一个数据库对应一个 SessionFactory
通过 SessionFactory 获取 Session 实例有两个方法, openSession() 和 getCurentSession()
openSession 获取的是一个全新的 Session
getCurentSession 获取和当前线程绑定的 Session,利于事务的控制,可以猜出,第一次调用的时候其实也是调用的 openSession 方法,只不过会做一些处理
如果要使用 getCurentSession 的方式获得 Session,需要事先在 cfg 配置文件中配置
<property name="current_session_context_class">thread</property>
使用 getCurentSession 创建的 Session,在 commit 或者 rollback 后会自动关闭,但是最好还是手动关一下
使用 openSession 查询数据不需要使用事务,但是如果使用的是 getCurentSession 查询也需要开事务
事务通常有两种,本地事务和全局事务
本地事务:针对一个数据库的事务(比如上面所配的 thread)
全局事务:跨数据库的事务(可以配 jta)
简单说说全局事务的实现,其实就是利用了一个 List ,每次执行数据库操作都会进行检测,如果发现里面含有未完成事务(会有一个标识),无论是那个数据库的事务没有成功都会进行回滚,这样就达到了全局事务的功能,不过一般都是在 web服务器中进行配置
Session接口
看过 SessionFactory 再看 Session 就简单了,就是用来操作数据库的,和 JDBC 中的 connection,进行 CRUD 操作
Session 可以看作是持久化管理器,它是与持久化操作相关的接口
- 删除一个对象(记录):delete 方法
- 查询一个对象(记录):get/load 方法
说说这两个方法的区别:
get 方法:直接返回实体类,如果查不到数据就返回 Null
get 先到缓存(Session 缓存/二级缓存)去查找,如果没找到就立即向 DB 发送 SQL 去查
load 方法:会返回一个实体代理对象 ,可以自动转换成实体对象;但当代理对象被调用的时候,如果数据不存在就会抛异常
load 也先到缓存(Session 缓存/二级缓存)去查找,如果没有就返回一个代理对象,等后面使用到这个代理对象的时候再去 DB 查,所以是支持延迟加载的(lazy)
所以,如果你能确定数据库中有这个对象就用 load ,否则就用 get,这样效率高
通过修改配置文件可以取消延迟加载(懒加载)在 class 标签里设属性 lazy - 修改一个对象(记录):update 方法
- 保存一个对象(记录):save 方法
Query接口
查询简单的可以使用 get/load 方法,如果需要复杂的查询,就要用 Query 这个接口了
先简单说下 hql 语言,是用来操作数据库的,不用担心数据库的类型,会进行自动转换,所以,只需要会写 hql 大部分操作就可以搞定了,多使用在业务逻辑层
下面是一个简单的栗子:
1 | Session session = HibernateUtil.openSession(); |
拓展下,除了 Query 还有一个用于查询的是 Criteria,它是纯面向对象的,但是并不常用,不多说,还有一种叫本地化 SQL 查询,说白了就是使用原生的 SQL 语句(返回的也是每一行的记录数组,可以使用 addEntity 方法来注入到对象中),也是不推荐使用,因为和数据库耦合了,除非是非常复杂的 SQL 语句,HQL 无法胜任的时候使用
query.executeUpdate() 可以执行更新、删除操作
分页查询
使用 Query 可以很简单的达到分页查询的效果,类似:
1 | // 第一条开始取,取 2 条,索引从 0 开始哦(MySQL 中使用的就是 limit) |
HQL语句
HQL(Hibernate Query Language)官方推荐使用的,功能强大
首先补充知识:
在设计数据表的时候,尽量保证每一张表都有一个主键,有利于对象的标识;如果表有主外键联系,先搞主表
关于主从表的设计,前面说过,简洁表示就是:从表依赖于主表(一般在从表建立外键,依赖主表的主键),从表对象直接引用从表对象,主表使用 set 集合引用从表,因为主表可能对应多个从表
HQL 语句的形式类似是:Select/update/delete…… from …… where …… group by …… having …… order by …… asc/desc 这样;另外就是 HQL 语句是区分大小写的,毕竟是面向对象的
和传统 SQL 不同,使用 Hibernate 的时候,建议是把表中的所有数据都查回来
使用 uniqueResult 默认只查一条,也就是说找到一条就不会再找了,提高效率:session.createQuery("...").uniqueResult() ;返回的也就是单个对象而不是 List 了
大部分语句和 SQL 还是很相似的,举几个常用的:from Userdistinct from Userdelete Person as p where p.id=?from User where age between 12 and 16 // 范围查询from User where age in (12,13,14) ;in /not inselect avg(age),name from User group by namefrom Lolicon where loli.age=16 // 因为 HQL 是代指的对象,可以直接用 . 来调用,前面的语句条件就是 Lolicon 对象里引用的 loli 对象的 age 属性
如果是部分查询的话,就是不查所有字段,那么 Hibernate 不会给你封装成 Bean 对象的,返回的 List 是一个 Object[] 的 List;获取数据需要先通过 list.get(index) 获取 Object 数组,然后再从数组里取出值
特别注意:如果查询返回的数据只有一列 ,那么 List 中存的就不是 Object 数组了,是单个的 Object 对象
因为只有一列,List 中存的每一个对象表示一行数据,既然只有一列就不需要数组了查询外的语句(增删改)需要使用 executeUpdate 方法才行
Hibernate 还支持把 HQL 语句配置到 xml 文件(一般是 hbm 配置文件)中去,使用 query 标签存储,获取的时候使用 getNamedQuery 方法获取,这样可以在不修改源码的情况下更改查询语句,实际中用的并不多
参数绑定
在 JDBC 中都用过,使用参数绑定有三个很大的好处,1.可读性强 ;2.效率高 ;3.防止 SQL 注入
参数绑定可分为两种:
1 | // 参数绑定 1 |
总结来说就是 :key 和 ? 的区别,第一个设置参数只能使用 key,第二个只能使用索引
连接查询
内连接:如果使用的对象中已经引用了其他对象(通过映射文件可以确定其表)是可以直接用的:from User u inner join u.boss
左外连接和右外连接也是类似就不说了,左外连接就是始终显示左表的数据(Null 不会被过滤)
其他的,还有就是迫切内连接 ;他会把右表的数据填充到左表中去,使用 fetch 关键字:from User u inner join fetch u.boss
迫切左外连接和右外连接也是类似,记住 右表填充到左表 就行了
其他用法
关于 HQL 还有些神奇的用法,比如可以这样用:select new User(user.name,user.age) from User user
但是这里有一个问题必须注意,那就是这时所返回的 User 对象,仅仅只是一个普通的 Java 对象而以,除了查询结果值之外,其它的属性值都为 null(包括主键值id),也就是说不能通过 Session 对象对此对象执行持久化的更新操作,并且需要有相应的构造函数
其实没必要这么麻烦
更多关于 HQL 的内容参见:http://www.hongyanliren.com/1901.html
缓存
Hibernate 使用到的缓存也就两级,Session 缓存也被称为是一级缓存,存在内存里
除此外还有个二级缓存,存放于内存和硬盘之间
使用 load 查询只是在缓存里查,等使用的时候才去 DB 里找,并且会返回一份存在二级缓存中,如果再进行反复查询,到达一定频率后会被转移到一级缓存中去
关于二级缓存,可以在配置文件中配置是否开启,使用缓存能减少对数据库的访问次数
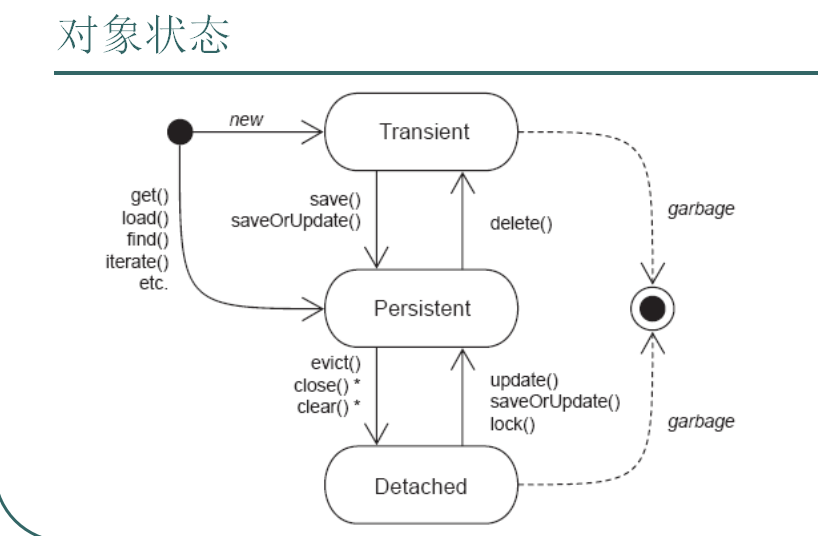
对象状态
Hibernate 中的对象分为三种状态:
- 瞬时(transient)
数据库中没有数据与之对应,超过作用域会被 JVM 回收;一般是 new 出来的,并且与 Session 没有关联的对象 - 持久(Persistent)
数据库中有数据与之对应,与 Session 有关联,并且相关联的 Session 没有关闭,事务没有提交
持久状态对象发生变化,在事务提交时会影响数据库中的数据(Hibernate 会自动检测到) - 脱管/游离(detached)
数据库中有数据与之对应,但是当前没有 Session 与之关联;当对象发生变化时,Hibernate 并不能检测到
比如,现在创建了一个 Domain 对象,那么就是处于瞬时状态,随时有可能消失;
当调用了 Session 的 save 方法后,就变成了持久态,这时数据库已经有一些数据了;也就是说 save 以后还是可以更改数据的,最后事务提交的时候还是会反映到数据库中
当调用了 commit、close 方法后就变成了游离态(commit 后一般会自动关闭连接),当数据改变后必须进行 update 才能反映到数据库中去
和线程的几种状态比较类似,可运行啊、阻塞啊
补充
pojo
前面说的 Javabean 也好、Domain对象也好都是一个东西,它其实还有个名字叫 pojo
不过它比较特殊,它在 bean 的基础上有几个要求,我可能重复了一些:
- 和一张表对应
- 需要一个主键属性,用来标识一个 pojo 对象
- 除了主键属性,还有其他的属性
- 有一个空的构造方法
连接/会话
如何判断目前开了几个数据库连接,可以看看进程,查查数据库端口的进程有几个,比如在 win 或者 linux 都可以使用命令:netstat -an 来判断
关于表设计
这个我记得在前面是说过的,尤其注意下多对多的情况,实际中
如果出现了多对多的情况,通常都会转换成两个一对多或者多对一的情况,也就是往两张表中间再加一个映射表,其实就是数据库设置中的那三范式;在 Hibernate 的 hbm 配置文件中可以看到相关的配置
多对一(或者一对多)和一对一的主要区别就是一对一的外键多了个唯一约束,并且外键列还多用于设置为主键(基于主键)
自动建表
开始提到的有种开发方式是先建立 Domain 对象,然后 Hibernate 会自动帮你建表,这个需要在 cfg 配置文件中进行配置
1 | <property name="hbm2ddl.auto">update</property> |
- create :每次加载配置文件都会创建,如果存在就会先删除,然后重新创建
- update :如果表不存在就会创建;如果表存在,并且表结构没变化就保留,如果表结构有变化就更新
- create-drop :在显式关闭 SessionFactory 的时候会把表给删除,用的很少
- validate :每次在插入数据之前都会检查表结构是否一致,用的很少


评论框加载失败,无法访问 Disqus
你可能需要魔法上网~~