这两天看 Struts 真是看的一脸懵逼,一方面不禁感叹牛人的思想就是超前啊,这篇笔记写的很急,其中的理解可能有些错误,想以后有了深入认识再回来修正的…..
不禁感叹 Struts2 与 Struts1 真是天差地别啊…. webwork 真厉害呢…
Struts1和Struts2
这个网上随便一搜就有N多的文章,分析的都挺详细的,我呢就说说主要的(我知道的)几点
关于 Struts1 我也写了一篇,不过没放在博客上,因为毕竟现在基本已经没人用了啊…..
地址在这:Github
Struts1-基于Servlet
为什么会被淘汰,这当然是因为有缺点的,抛开它奇葩的命名不说,重要的是架构不是很好,体现在下面的几点
- ActionServlet 的任务过于集中,压力大,不容易扩展和维护
它主要做的有:处理请求、实例化 formBean,往里封装数据、然后根据配置文件决定是否进行校验,对结果进行处理,最终把结果封装到 request 中、实例化相应的 Action ,调用相应的方法,传递相关的对象、对 Action 返回的结果进行处理,如转发到指定页面…..;
如此多的功能集中在一起必然扩展性很差,也容易出问题 - Action 是单例的,线程不安全的
Action 被创建出来后会一直存在,并且只存在一个,就像 Servlet,一个 Action 处理所有的请求(数据不安全,不要在 Action 中声明实例变量) - ActionForm 造成类的爆炸
因为一个表单就对应一个,虽然可以使用动态 formbean ;一个用户(请求)可能对应好几个…因为 formBean 是随 Action 存在的,一个 Action 可能会处理多个表单 - 耦合性高
从execute(ActionMapping mapping,ActionForm form,HttpServletRequest request, HttpServletResponse response)这个从方法的参数就可以看出,需要传入四个参数呐!
Struts2-基于Filter
新一代,然而和一代并没多大关系,倒是和 webwork 的关系挺大
- 分离关注思想
和 aop 挺像,嗯?反正就是不像一代那样集中在一个组件上了;将 web 开发中的常规任务剥离开来,分别交给不同的组件(拦截器)进行处理,比如:文件上传、表单的处理、国际化、参数传递、类型转换等等 - Action 是原型、独占的,不共享
意思就是说一个请求对应一个 Action,所以可以存放客户端的状态信息了! - 取消了 ActionForm ,使用 pojo(action、javabean)接收数据
- 松耦合,可维护性高
action 就是个普通的 pojo 也就是普通的 javabean,也就是说 struts2 api 和 原生的 servlet api 关系不大【非侵入性,不用实现你的接口也不用继承你的类,这是理想条件下】
Struts2的使用
搭建就不说了,就是拷进去相应的 jar包,创建的 action 不需要继承任何类或者实现任何的接口
下面说下配置,Struts2 是基于过滤器的,所以需要在 web.xml 文件里配一个过滤所有请求的过滤器,我用 IDEA 建了个项目,发现都给配好了
1 | <filter> |
先来写个简单的 Action,相比 Struts1 就简单多了,不需要继承任何类,方法名默认还是用 execute (应该是 webWork 规定的)
1 | public class HelloWorld { |
然后是 Struts 的配置文件,默认在 src 下名字为 struts.xml ;至于这个文件怎么写,不知道,那就抄吧,在 Struts 的核心包里有相关的配置文件,照着写写就差不多(struts2-core.jar 下的 struts-default.xml 有返回值等大部分配置;struts2-core.jar/org.apache.struts2/default.properties 文件下有绝大部分的变量说明)
1 | xml version="1.0" encoding="UTF-8" |
关于 namespace 命名空间的作用,就是在输入网址的时候用的,比如: http://xxx:8080/webAppName/namesPace/Action
最后配置的那个 action 是动态调用,它对应多个返回值,也就是对应多个方法,可以接受很多的请求,并且使用了通配符,通配符匹配到的会传给后面的 {1} 中,比如这样用:http://xxx:8080/webAppName/namesPace/HWAction_save ;下划线后面跟的是方法名,如果省略将会匹配默认的 execute 方法
对于多个方法的访问,除了写多个 action 外
还可以使用这样的地址访问:http://xxx:8080/webAppName/namesPace/Action!methodName
这样的话只需要在 method 里指明方法名就行了,不过用叹号分割总感觉怪怪的,并且在 Struts 的配置文件中开启动态方法调用才会生效。所以还是像上面那样配置吧
上面提到了可以不配 class 走默认设置的全局 class,这个具体是应用在请求 WEB-INF 目录下的文件的,因为默认的 class 是 ActionSupport ,它实现了 Action 的接口,所有有一个 execute 方法,这个方法返回字符串 success,所以说只需要配置:<result name="success">/WEB-INF/index.jsp</result> 就可以实现请求保护目录下的文件,而不需要写相应的 Action
获取参数
url 可以传参,但是 action 中并没有继承任何类,如何获取 request 等对象呢,是通过 ServletActionContext 的静态方法获取的;但是获取 url 中的值并不需要这么麻烦,前面说过,action 其实就是一个 javabean,那么就可以设置属性,属性名对应传进来的参数名,调用的时候会自动用反射技术进行设置的;所以说在方法中直接用就行了
如果需要数据回显,还是用标签库(其实是从值栈中获取):
1 | <%@ page contentType="text/html;charset=UTF-8" language="java" %> |
再来说说 ServletActionContext ,它可以获取到绝大数需要的对象,它其实是 ActionContext 的孩子,下面会详细说
数据处理
我们知道开发的 web 应用中存储数据有四个域,从小到大依次是:page 、 request 、 session 、 application
在 struts 有个比较常用的是 ActionContext 说到 Context 也就是上下文,指的其实就是环境,也就是当前的环境,同时还可以说是数据中心
在 ActionContext 中封装了其他域的引用,具体有:
- request
- session
- application
- valuestack(值栈)
值栈肯定是个栈,然而其实是通过 arrayList 进行模拟的;值栈其实存在于 request 一个特殊的属性 struts.ValueStak 独立出来是为了方便
s:property 标签默认就是去值栈里进行寻找 - parameters
- attr
会自动从 session/request/application 域中去寻找
ActionContext 于内部的六个“域”是双向引用!ActionContext 属于 threadlocal 俗称线程本地化;ServletActionContext 是 ActionContext 的子类,进行了一些简单的封装;所以有了很多的 get 的方法获取到相应的对象
通常还是推荐尽量使用 ActionContext 来获取数据,因为获取的是 Map 集合,不需要加入 servlet API 的 jar 包,也就是说解耦了;但是有些功能实现不了的话还是需要用 servlet 中的对象(比如获取路径)
另外,ActionContext 还可以这样用:Map<K,V> map = ActionContext.get("request") 这样获取到的是 request 的 Map 集合
ActionContext 的 put 方法默认是直接存到 request 域
get(“request”).put 方式是存到 request 的 map 集合中去
所以说,在用 OGNL 表达式取的时候,第一种可以直接#key这样取;而第二种要使用#request.key或者#attr.key的方式来取值put 方法像是 Struts 的一种优化,为了方便取值,因为值栈说白了就是存在于 request 域中的
通常,Action 会被放在值栈根节点的栈顶(双向引用哦),这个操作是在执行过程中执行的(下面的工作原理),表单的提交、数据的回显都是依赖于值栈
然后再说下属性链,Action 其实是个 javabean,在 Action 中还可以再引用一个 bean 作为属性,传参的时候就需要指明了:http://xxx:8080/webName/action?user.name=loli 这就是给 action 中的 user 属性的 name 属性赋值,额…说的这么别扭
这里有个坑,当你在 action 用 javabean 类型的属性时,千万别用一个小写字母开头,比如:mUser
因为这样在生成属性的时候会变成这样:getMUser() ;这就很尴尬了….这是不符合规范的,所以,别这么搞
补充一个专业术语:action 相关
说的是很多资源文件需要和 action 放在一起,文件名相同,扩展名不同,至于什么用处,相当于一代的国际化资源文件吧,下面的表单校验中用得到
工作原理
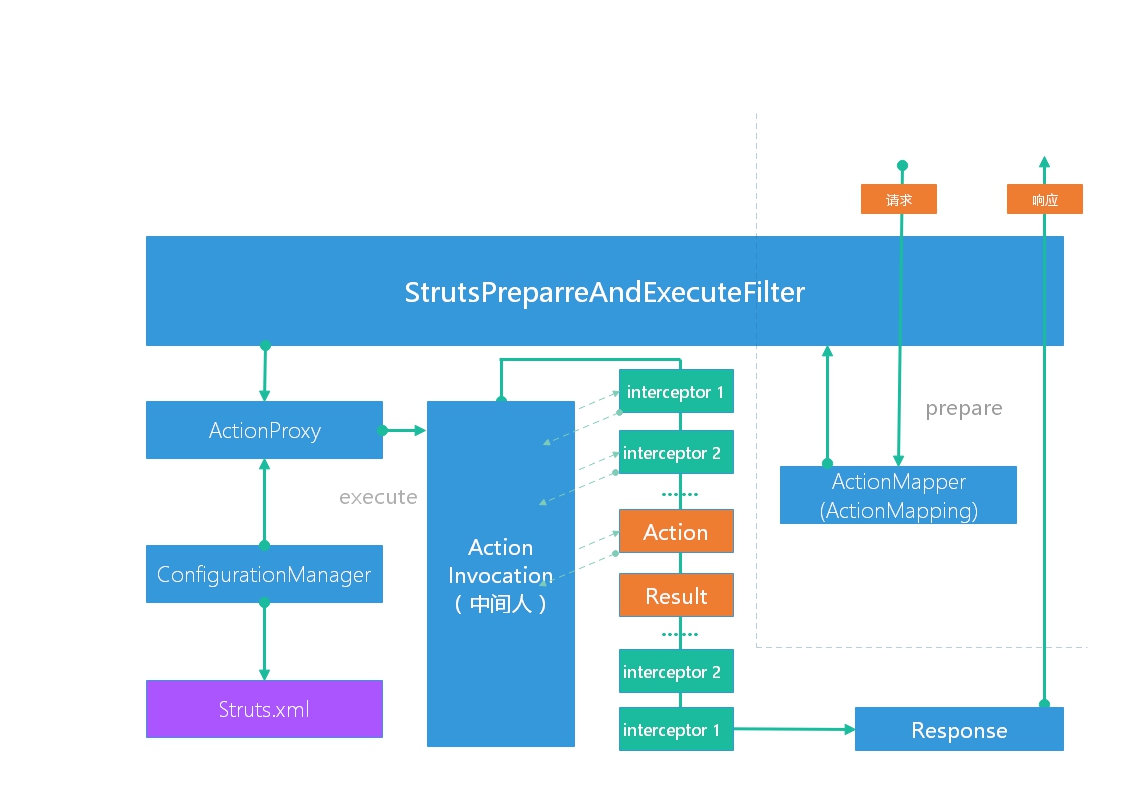
图画的不是很准确,差不多这意思,请求来了都要进入 StrutsPreparreAndExecuteFilter 这个核心过滤器,StrutsPreparreAndExecuteFilter 主要有两个操作(对象),一个是准备(prepare 图的右边);另一个是执行(excute 图的左边);
prepare 会注册国际化资源文件,并且会创建 ActionContext 对象,顺便绑定到当前线程中去….(创建的过程还是蛮复杂的,想知道的看源码….)
接下来会查找 ActionMapping,如果没有就创建(通过 ActionMapper 来寻找/创建),最后存到 request 中去
另外还会参与过滤模式的处理,就是过滤出 Action 的请求,其他的请求(jsp、img等)直接放行
在核心过滤器中,会发现刚开始是加载配置文件,如果没有特别的指定会自动加载3个配置文件,第一个是 Struts2 核心包下的 struts-default.xml 文件,最后一个是我们自己配置的 struts.xml 文件
struts-default.xml 文件里配了一些东西,比如刚开始的一堆 bean,后面就是定义了一些 Type(result-types)比如最常用的 dispatcher 和 redirect,其中可以看到 dispatcher 被设置为了默认,所以在我们自己配的配置文件中如果设置转发不需要配 Type
再下面就是初始化拦截器(拦截器只能拦截 Action,是 Struts 中的概念),这应该就是 Struts2 的核心了;定义默认的拦截器、默认执行的 Action
上面的操作完成后最终会到达 excute;判断如果 mapping 不为空,就调用 excute 执行 Action 会把 mapping 一起传过去,执行玩后到此终止,也就是说它没放行,后面的过滤器不会自动执行!
在调用 Action 的方法中 excute 会创建出 ActionProxy ,它依赖于 ConfigurationManager 把配置文件(Struts.xml)读取出来进行一些处理,然后会请求一个中间人(Action Invocation)来调用那 N 个过滤器(应该是13个,具体看配置文件,叫做过滤器栈),使用的是递归方式,也就是上图的虚线,调用 1 然后返回(返回时再次调用此方法,也就是调用第二个拦截器),再继续调用 2 再返回….
在 Action 调用之前处理的叫预处理,之后处理的叫后处理,大部分后处理是空实现,文件上传的过滤器比较特殊,因为需要在后处理里删除缓存文件
应该是在调用拦截器之前 excute 会把 action 置为栈顶(值栈)
如果配置自己的拦截器,一定要放在 Struts 拦截器的上面,因为 Struts 拦截器并不会放行
其他拓展
ActionSupport
这个类实现了 action 和其他几个有用的接口,比如数据的校验、国际化;你的 action 继承它后会自动获得这些能力
基本校验&文件上传
主要是通过拦截器和接口实现的 ActionSupport 实现了两个接口和默认栈中一个拦截器配合使用
DefaultWorkflowInterceptor 提供了基本的校验功能(其实它只是判断是否有错误,有就跳转到 input 设定的页面,而不会再执行 Action 了)
关键的调用在校验拦截器;所以 DefaultWorkflowInterceptor 就是工作流嘛,应该可以理解为重新定义路由….额
先来写个注册页面,使用到了标签库,很贴心的会自动显示校验错误,不需要任何标签:
1 | <%@ page contentType="text/html;charset=UTF-8" language="java" %> |
为了兼容直接访问 JSP 的情况(虽然极少)最好把 namespace 写上,这里顺便使用了文件上传的过滤器,文件的信息会自动装填到相应的字段,比如文件的类型会自动装填到下面的 imgContentType 字段,类型是 MIME 的,在服务器的 web.xml 中有相应的定义,相应处理请求的 Action :
1 | public class RegAction extends ActionSupport { |
Action 中,validate 校验方法优先于其他方法执行,但是校验过滤器是在参数过滤器之后的,没有参数校什么校;相应的配置文件:
1 | <package name="regPkg" namespace="/reg" extends="struts-default"> |
关于 addFieldError 方法,它是先由校验拦截器调用的,然后才是 DefaultWorkflowInterceptor 进行判断,就是判断是否有错误消息啦;如果有就路由到 input 设置的界面了
addFieldError 方法会将错误信息加入到一个 Map 集合中去,然后在后续的 JSP 页面中就可以从这个集合中取出这些信息
关于配置文件,可以采用模块化思想,就是有多份文件,在主文件中使用 include 引用;
校验&文件上传的补充
上面使用的注解的方式避免 toReg 方法被校验,这种方法只限于在这个环境(拦截器)下使用;除了这一种还有其他两种方式,并且这两种方式是通用的,在其他的拦截器也可以使用
加后缀法指定校验方法
1
2
3
4
5
6// 看方法名,后面跟需要校验的方法名,或者使用 validateDoReg 也可以
public void validateReg() {
if (name == null || name.isEmpty()) {
addFieldError("name",getText("error.name.empty"));
}
}配置文件法:在需要处理的 Action 下覆盖默认的配置
1
2
3
4<!-- 去校验的第三种方式:覆盖法指定跳过的方法,这个写法在配置文件中也可以找到 -->
<interceptor-ref name="defaultStack">
<param name="validation.excludeMethods">input,back,cancel,toReg</param>
</interceptor-ref>
在文件上传的时候,我们可能要限制文件上传的大小,这个在 Struts 的配置文件中设置下 struts.multipart.maxSize 的值就可以了
还比较常用的是限制文件类型,也就是指定某些类型的文件才能上传,这个用 fileUpload 拦截器就可以做到,这种方式类似是注入了,可以找到其类中具体对应的属性,具体配置是:
1 | <interceptor-ref name="defaultStack"> |
这里提一下,一旦配置了 Action 的拦截器(interceptor-ref)就不会继承包配置的默认的拦截器栈了,所以如果配置其他的拦截器别忘了加入 defaultStack
这些内容在测试代码中都有,还有文件的下载,篇幅太长就不写了,详见 Github
使用验证框架
上面所写的是实现 validate 方法,其实还可以用 Struts2 提供的框架,配置下 xml 文件就行了,具体的约束在:lib/xwork-core.jar!/xwork-validator-1.0.2.dtd ;嗯….是的,在 xwork 下
然后创建 Action 相关文件,在需要进行校验的 Action,名字类似:ValidateAction-validation.xml ;其他的都一样,都是用 ValidationAware 接口存储错误信息,用 workflow 拦截器导向 input 界面,一个例子:
1 | xml version="1.0" encoding="UTF-8" |
msg 可以使用其 key 属性从国际化资源文件中提取,当然在其中也是可以使用 OGNL 的
如果验证指定方法文件名就要改成:ClassName-ActionName-validation.xml
主题与国际化
这两方面简单说下吧,我没仔细看呢….Orz
struts2 默认带了 4 套主题;可以通过设置常量的方式来指定框架使用那个主题:struts.ui.theme=xhtml ;默认就是 xhtml
不同的主题在生成 html 的时候会有所差异。这几个主题什么区别自行搜索吧
如果某个标签 Struts 渲染的你不爽,那么是可以修改的,比如说错误的那个标签;因为 JVM 是先加载 jar 包,然后加载 src 里面的代码,如果在 src 里有相同的包,相同的文件,那么就会覆盖之前的(改 ftl 模板文件就行)
关于国际化拦截器,他会检测请求是否传入了 request_locale 参数,如果有就将其存储到 session 中,并且更改其对应的语言(就是加载相应的国际化资源文件)并且其实还存了一份到 ActionContext 中,就是那个大 Map,便于数据的回显
资源文件按照:文件名_语言_地区 的形式,比如:name_zh_CN ,类型当然是 properties;加载国际化资源使用的是常量的方式,键是 struts.custom.i18n.resources 值就是你写的 prop 文件的位置了,同一类加载一个就行(默认的那个 name.properties),多个用逗号分割;记得在 JSP 的标签中使用 <s:text> 标签的 name 属性获取值
模型驱动拦截器
也许配合 笔记2 效果更好,因为哪一篇太长了(这一篇好像更长了),写在这里了….
先说它的作用,其一:
OGNL 表达式是从栈顶的对象里找数据,对象里的对象里的值是没办法直接用的,只能使用属性链,使用模型驱动后,会在栈中压入一个自定义的对象,在 Action 的上面,所以在 JSP 中可以直接用这个对象里的属性,表单提交的数据也是进这个对象
其二,也是主要作用:
对所有的 Action 模型对象进行批处理;比如:在一个可以拦截所有 Action 的拦截器中判断(instanceof)是否是 ModelDriven,如果是就强转成 ModelDriven,调用其 getModel 方法就可以获得其要操作的对象;然后就可以利用反射进行实例化….等
使用模型驱动需要实现接口 ModelDriven<T>,以及实现 getModel 方法,这个方法返回的就是要压入栈顶的那个对象
更进一步使用:
模型驱动拦截器是在参数拦截器之前的,如果想要在模型驱动将对象压入栈顶之前初始化(填充)对象,可以使用准备拦截器(翻译不是很准确);需要实现 Preparable 接口,此方法会在模型驱动拦截器之前调用
如果需要传进的参数数据,要用 paramsPrepareParamsStack 栈,因为如果用默认栈,准备拦截器是优于参数拦截器的,那样就会取不到参数
具体的测试代码我放在 Github
其他配置
发现一个标签对于调试很爽,并且使用简单:<s:debug />
加上后会显示一个连接,点击会展示值栈、ActionContext 等的情况
Action 类中,如果加上 private static final long serialVersionUID = 1006766693264599611L; 是反序列化时用的,具体还没研究
关于校验详细的流程写的不太详细,先这样吧….
Struts2 的根配置文件除了前面所说的,可能还会用到的有:
1 | <struts> |
最后补充:关于转发,如果是使用链式(type=chain)转发到另一个 Action,那么它们两个都是在一个线程中


评论框加载失败,无法访问 Disqus
你可能需要魔法上网~~