学习之前先要弄明白的是:什么是 JDBC?
SUN 公司为了简化、统一对数据库的操作,定义了一套 Java 操作数据库的规范,称之为 JDBC
我们要操作数据库,需要有数据库厂商提供的驱动,但是它们的规范很可能是不同的,难道我们要把所有的数据库规范都看一遍?学习成本太高,不利于推广啊,于是 sun 公司就搞了个 JDBC (接口),所有的驱动按照它的规范来,这样我们用的时候只要导入相应的驱动,代码统一使用 JDBC 的规范就可以了,降低了学习成本
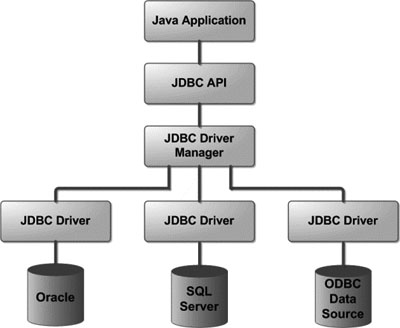
其实 Servlet 也是一样的思想,也是接口,是一种规范;比如我使用的是 Tomcat ,那么具体实现就是 Tomcat 来完成的,这就是我们为什么要导入 Tomcat 中的相关 jar
我的机器只有 MySQL 的,所以我就只是用的它做的测试,驱动下载的官方地址:
https://www.mysql.com/products/connector/
使用 IDEA 的同学可以直接在 DATABASE的侧边栏 设置里自动下载哦
基本套路
使用 JDBC 的基本套路可以用下面的代码来表示,一共六点
需要注意的是:java.sql.* 和 javax.sql.* 都属于 JavaSE 了,所以建个普通工程就可以用
1 | public class Main { |
在第一步的加载驱动的时候,有两种方法:
第一种不推荐,因为首先它会被加载两次(可以看源代码中的静态代码块),其次会有强依赖性,必须要 import 相关 jar 包;
而第二种只需要一个字符串而已,在更换数据库的时候更方便。
不得不再感慨,IDEA 的代码提示救了我这英语白痴+健忘,连 SQL 语句和配置文件的内容都可以提示…..
防止在读取/存储时中文出现乱码,记得设置 url 的时候,结尾加上 ?useUnicode=true&characterEncoding=UTF-8 ,如果报错了,反正就是提示 url 有问题,那么可以尝试转义一下试试,转义后的 url 为:?useUnicode=true&characterEncoding=UTF-8
学过 html 的都懂哈….
Statement对象
从上面的代码也可以看出,这个是用来向数据库发送 SQL 语句的;常见的几个方法有:
- executeQuery()
执行查询语句,返回一个结果集 - executeUpdate()
执行增删改语句,返回影响的行数;判断是否大于 0 来判断是否执行成功 - execute()
执行所有的 SQL 语句,但是一般不太用,因为它返回的是一个 boolean ,代表是否执行成功
比如查询,我们还需要判断、再用 getResultSet 来获取结果集,太麻烦
preparedStatement对象
在实际中,其实使用 preparedStatement 的情况比较多,从名字上就可以猜出它与 Statement 一定关系不一般
statement 和 preparedStatement 的区别:
- preparedStatement 是 statement 的孩子,也就是 preparedStatement 继承自 statement
- preparedStatement 可以防止 SQL 注入问题,设置的参数会被转义
- preparedStatement 可以对 SQL 语句进行预编译,提高效率
1 | public void test() { |
JdbcUtils 的写法可以参考:Github
ResultSet对象
查询返回的结果集,可以简单理解为一个表格,有一个游标,和 Android 一样默认是指向第一行之前 ;所以一般是先进行 next 获取
它提供了一堆的 get 方法,获取各种类型的数据,当然无论那种数据都可以使用万能的 getObject
所有的 get 方法都提供了两种重载,可以使用索引号或者列名获取一行的数据,注意索引从 1 开始 ,为了更直观,一般不会使用索引来获取;如果结果集只有一列,那么用索引就比较方便了
如果结果集只有一行数据,可以使用 if(resultSet.next()){} ,有多行就要用 while(resultSet.next()){} 来循环取出
其他的常用方法:
- 下一行:
rs.next(); - 上一行:
rs.previous(); - 移动到指定行:
可以是负数!如果传入1,相当于first();;如果传入 -1 ,相当于last();
滚动后是可以直接取数据rs.absolute(indexNum); - 移动到最前,第一行之前
rs.beforeFirst(); - 移动到最后,最后一行之后
rs.afterLast();
批量操作
如果想要同时执行多条 SQL 语句,那么一条一条的去执行看起来比较弱鸡,资源开销太大,效率太低,所以肯定有批量的法子啊!就是这么自信
既然执行 SQL 语句有两种方式,那么类似的批量操作应该也有两种方式 : 使用 statement 和使用 preparedStatement
使用statement
非常非常简单,直接上代码:
1 | // 可以同时执行不同类别的语句,但是效率低 |
就是通过 addBatch 方法添加进 List 集合,然后 executeBatch 一起执行,再用 clearBatch 清空 List
就当作 createStatement 方法返回的 st 内部维护了一个 List 集合嘛~我也没看源码实现,应该是差不多的 (:雾
使用preparedStatement
其实它们是比较类似的,事实上这一种用的比较多
1 | // 只能执行相同的语句,用于批量插入、更新等;效率高 |
和上面一种基本一致,只能预编译一条 SQL ,所以……
因为 List 存在内存中,JVM 的内存也是有限的,所以如果要执行很多条 SQL 的话建议分段
就向上面一样,每满多少条就执行一下,然后清空 List
当然我这里设的 10 太小了,只为测试,设个 1000 应该也不多,具体多大凭感觉…
调用存储过程
至于什么是存储过程我在 MySQL 的文章中说过了,简单说就是一个函数;所以也就是说如何调用函数了
1 | public static void main(String[] args) { |
关键在于使用 prepareCall 来调用函数,在 MySQL 中,函数的返回值也写在参数,这是不太一样的地方,总之还是比较简单的
获取自动生成的键
在插入数据的时候,如果某一列我们设置为自动增长,通常也设置为主键,这样在插入的时候就不需要管这列了,但是如果后续操作需要用到这一列,那就得再查询一次,这样肯定不爽,所以要自信的认为有个插入数据的时候会返回这列的值的方法;也就是说这东西可以返回它自动生成的值
当然, 仅对于 insert 有效,因为只有插入的时候才会生成 ID
1 | private static void getID() { |
官方 API 上说:
获取由于执行此 Statement 对象而创建的所有自动生成的键。如果此 Statement 对象没有生成任何键,则返回空的 ResultSet 对象。
注:如果未指定表示自动生成键的列,则 JDBC 驱动程序实现将确定最能表示自动生成键的列。
关于表设计
一般来说一个对象(javabean)对应一个表,大部分也就是下面的几种情况
当两个表有关联的时候,比如一对多,对应到 bean 中就是主 bean (相当于主表)中有个 set 集合保存子 bean ,子 bean 包含一个主 bean 类型
一对多/多对一
- 先不要管映射关系,先设计出基本的属性
- 在多的一方加外键描述
但是呢,尽量不要使用一对多,能不用就不用,因为有时候做查询,返回有太多的数据会导致内存溢出,具体可以考虑显示的需求,如果“一”中不需要显示“多”,那么就不需要查询多的一方了
多对多
- 先不要管映射关系,先设计出基本的属性
- 设计一个中间表,一般两列;命名为:两个表名中间用
_连接 - 中间表要加约束,对应各自的 id , 当然也可以使用联合主键保证不重复
一对一(主从关系)
- 先不要管映射关系,先设计出基本的属性
- 从表要加外键约束、非空、不能重复、来自主表
某些情况可以把主键设置成外键所在列
自连接
- 先设计基本属性
- 设计一列,增加外键约束,约束来自本表,不要加非空
名字参考:parent_id
主要是用来做无限分级(比如分类表),但是如果层次太深查询使用递归的时候就很容易导致内存溢出,有一种解决方案是使用树结构(树状节点),其实就是二叉树的先序遍历,这个以后再说吧
其他注意
Connection 连接非常的宝贵,因为数据库支持的连接数是非常有限的,所以要遵循 尽量晚创建,尽量早释放 的原则;提示,释放连接的代码要写在 finally 里,来确保一定会释放,一般的套路是:
1 | public static void main(String[] args) throws SQLException, ClassNotFoundException { |
关于 JDBC 中 Java 和 MySQL 对应的数据类型到这里查看:
http://wiki.jikexueyuan.com/project/jdbc/data-types.html
JDBC 的使用其实有很多重复代码,最好使用抽出来形成一个工具类,比如获取 conn 和 释放连接的方法,就像上面给的地址中的那样
更多的内容,比如事务等下次再写吧…


评论框加载失败,无法访问 Disqus
你可能需要魔法上网~~