顺便说说比较实用的一个功能,虚拟化环境,使用的是 Virtualenv
爬虫的简单架构
首先分为几个模块,首先还要有一个调度端,来负责启动爬虫、停止爬虫、监视爬虫的状态
在爬虫模块中主要有:URL 管理器、网页下载器、网页解析器
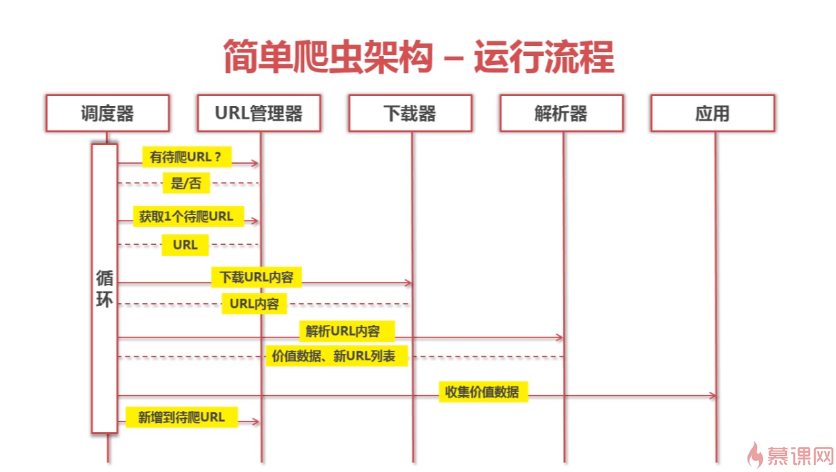
具体架构和运行流程见下图,说的非常清楚了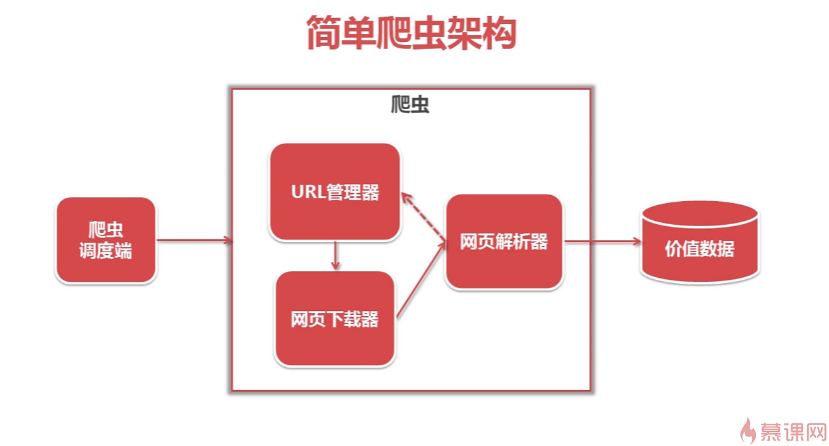
urllib库
在 Python 3.x 里,urllib2 改名为 urllib,被分成一些子模块: urllib.request、urllib.parse 和 urllib.error。尽管函数名称大多和原来一样,但是在用新的 urllib 库时需要注意哪些函数被移动到子模块里了。
urllib 是 Python 的标准库(就是说你不用额外安装就可以运行这个例子),包含了从网络请求数据,处理 cookie,甚至改变像请求头和用户代理这些元数据的函数。这个库的说明文档在:https://docs.python.org/3/library/urllib.html
首先来看一下最基本也是最简单的使用:
1 | from urllib.request import urlopen |
当然有些网站可能会对爬虫进行屏蔽处理,这时候我们一般进行浏览器伪装,必要的时候要使用 Cookie,我目前遇到的加个请求头就可以了,这里使用到了 Request 这个类,比较简单,等后面再扩展
1 | # 添加请求头,伪装浏览器 |
Request 官方中文文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html#
BeautifulSoup
简单说,这个库就是来解析 HTML 的,通过标签将 HTML 进行结构化处理、展示,一切都是为了便于从杂乱的 HTML 获得有用的信息
由于 BeautifulSoup 库不是 Python 标准库,因此需要单独安装,最新的版本为 BeautifulSoup 4 版本(也叫 BS4 )我们可以通过 Python 的包管理 pip 命令进行安装:$pip install beautifulsoup4
像我,如果用的 PyCharm 可以直接在项目设置里搜索安装,或者直接先写上导入代码(from bs4 import BeautifulSoup),然后利用错误修正快速安装
好了,下面就来看看它的基本用法吧,也是官方提供的一段代码
1 | from bs4 import BeautifulSoup |
常见错误
在爬取网页的时候,常见的有两种错误,比如我们使用 urlopen 函数来打开一个网页,那么可能
- 这个网页不存在,就是说在服务器上找不到
程序可能会返回 HTTP 错误,比如 404 或者 500 之类的,这是 urlopen 都会都会抛出 HTTPError 异常,我们可以使用try...except语句来进行捕捉 - 服务器不存在
urlopen 会返回一个 None 对象,我们可以使用if html is None来进行判断下
除了上面最基本的两个,还有其他很多情况,比如获取到的网页内容并不是和我们预想的一样,这样的话,我们使用 BeautifulSoup 的时候就会出现问题
如果你想要调用的标签不存在,BeautifulSoup 就会返回 None 对象,如果再调用这个 None 对象下面的子标签,就会发生 AttributeError 错误,解决方案嘛,可以按照下面的代码来写
1 | from urllib.request import urlopen |
如果服务器不存在,上面代码中 html 就是一个 None 对象,html.read() 就会抛出 AttributeError
Virtualenv
我们知道所有第三方的包都会被 pip 安装到 Python3 的 site-packages 目录下。
如果我们要同时开发多个应用程序,那这些应用程序都会共用一个 Python,就是安装在系统的 Python 3。如果应用 A 需要jinja 2.7,而应用 B 需要 jinja 2.6 怎么办?
这种情况下,每个应用可能需要各自拥有一套“独立”的 Python 运行环境。virtualenv 就是用来为一个应用创建一套“隔离”的 Python 运行环境。也可以说是一个虚拟化环境
使用
首先,我们用 pip 进行安装
1 | pip install virtualenv |
然后创建一个目录,在这个目录进行初始化
1 | cd Test |
virtualenv venv 将会在当前的目录中创建一个文件夹(此例中是 venv),包含了 Python 可执行文件,以及 pip 库的一份拷贝,这样就能安装其他包了。虚拟环境的名字(此例中是 venv )可以是任意的;若省略名字将会把文件均放在当前目录。
有时也会加上 --no-site-packages 参数,这样已经安装到系统 Python 环境中的所有第三方包都不会复制过来,这样,我们就得到了一个不带任何第三方包的“干净”的 Python 运行环境。
还可以使用 -p 参数指定 Python 解释器,我这里只有 Py3
在 venv 环境下,用 pip 安装的包都被安装到 venv 这个环境下,系统 Python 环境不受任何影响。也就是说,venv 环境是专门针对 Test 这个应用创建的。
环境差不多已经配置完毕,下面就可以进入这个环境进行操作了,进入后当前虚拟环境的名字会显示在提示符左侧,然后就可以使用 pip 安装库,或者使用 Python 进入Py 的环境
1 | source venv/bin/activate |
完成工作后,可以使用下面的命令来停用、退出
1 | deactivate |
这将会回到系统默认的 Python 解释器,包括已安装的库也会回到默认的。
要删除一个虚拟环境,只需删除它的文件夹。(要这么做请执行 rm -rf venv )
virtualenv 是如何创建“独立”的 Python 运行环境的呢?
原理很简单,就是把系统 Python 复制一份到 virtualenv 的环境,用命令 source venv/bin/activate 进入一个 virtualenv 环境时,virtualenv 会修改相关环境变量,让命令 python 和 pip 均指向当前的 virtualenv 环境。
重定位
某些特殊需求下,可能没有网络, 我们期望直接打包一个 ENV, 可以解压后直接使用, 这时候可以使用 virtualenv --relocatable ./ 指令将 ENV 修改为可更改位置的 ENV
一般情况下,隔离环境都绑定在某个特定路径下。这也就意味着不能通过仅仅是移动或拷贝目录到另一台计算机上而迁移隔离环境。 这时可以使用
–relocatable来重定位隔离环境
$ virtualenv –relocatable ENV
不过这个命令在 Windows 下不能使用….也是实验性的一个命令
参考
可以看看我学习时写的花瓣网和百科的简单爬虫:Github
关于 BeautifulSoup 这里有份不错的中文文档:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/


评论框加载失败,无法访问 Disqus
你可能需要魔法上网~~